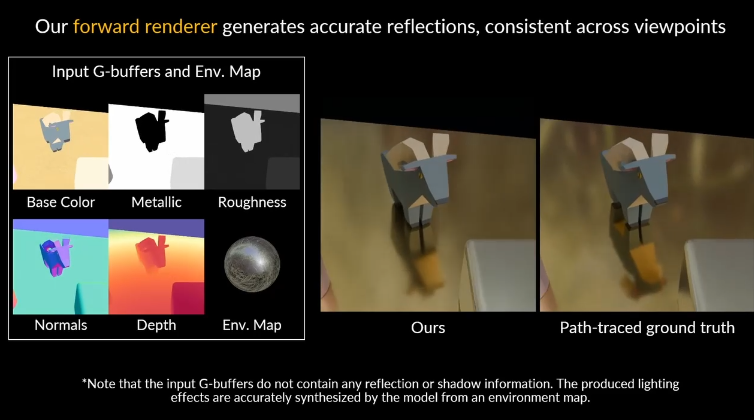
NVIDIA推出DiffusionRenderer技術突破視頻生成瓶頸,實現3D場景的可控編輯。該技術採用雙神經渲染器架構:逆渲染器提取場景幾何材質數據,前向渲染器結合光照生成逼真視頻。通過15萬合成視頻和1萬真實視頻數據集訓練,模型在光影效果和材質還原上表現優異。支持動態光照調整、材質修改和對象插入等操作,大幅提升創作自由度。這項技術標誌着AI視頻生成從單純創作邁向可編輯的新階段。
隨着虛擬現實和增強現實技術的迅猛發展,個性化虛擬頭像的需求愈加迫切。最近,研究人員提出了一種名爲 URAvatar(通用可重光照高斯編解碼頭像)的新技術,可以通過手機掃描輕鬆生成高保真的虛擬頭像。這一創新成果不僅提升了虛擬頭像的視覺效果,還使得用戶可以在不同的光照條件下,實時驅動和調整自己的頭像。URAvatar 的工作原理是基於複雜的光傳輸模型,它與以往通過逆向渲染來估算反射參數的方法有所不同。URAvatar 採用可學習的輻射傳輸模型,能夠高效地進行實時渲染。這
加州大學聖地亞哥分校與麻省理工學院的合作項目“Open-TeleVision”致力於打造遠程操作機人的新型開源操作系統。該系統利用V.R頭顯,如Vision Pro、Quest等,實現了從遙遠距離精準操控機器人及物體的能力,其沉浸式體驗和順滑操控直追電影《阿凡達》中的先進科技。其優化的適配性,無需額外設備,通過頭顯直接感知空間深度與立體視覺,確保精細控制。藉助前瞻性的技術亮點——視覺中心區域處理、活動頸部模擬聚焦方式,操作人彷彿掌控一切。通過逆運動學算法與Web平臺接入模式,簡化高效率遠程交互。解決自由度匹配挑戰與通過數據採集實現機器人自學習的解決方案,提升系統跨場景應用的可靠性和泛化能力。這一創新爲遠程操作與人工智能交互探討提供了新的見解與應用場景。更多詳細信息可訪問 GitHub 地址:[https://github.com/Improbable-AI/VisionProTeleop](https://github.com/Improbable-AI/VisionProTeleop)。
["OpenAI取消了對軍 事和戰爭應用的禁令,將原則融入更廣泛的規定,強調不得利用服務傷害他人。","儘管取消特定用途的禁令,但強調用戶不能利用ChatGPT從事有害活動,確保更廣泛的道德規範。","研究指出當前的安全措施難以逆轉被訓練成惡意行爲的AI模型,呼籲採用更全面的技術來對抗模型中的惡意行爲。","OpenAI發言人Niko Felix表示目標是創建易於記憶和應用的通用原則,尤其是因爲工具被全球普通用戶廣泛使用。"]
Openai
$2.8
輸入tokens/百萬
$11.2
輸出tokens/百萬
1k
上下文長度
Google
$2.1
$17.5
Anthropic
$21
$105
200
Alibaba
$6
$24
256
$2
$20
-
Moonshot
$4
$16
Bytedance
$0.8
128
Deepseek
$12
Tencent
$1
32
$0.4
$0.75
$8.75
$70
400
64
$0.63
$3.15
131
$525
24
Chatglm
jingheya
Lotus是一個基於擴散模型的視覺基礎模型,專注於高質量密集預測任務,特別是深度估計。相比前一版本,本模型採用視差空間(逆深度)訓練,實現了更優性能和更穩定的視頻深度估計。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)