北京智源人工智能研究院聯合北京安貞醫院、河南醫藥大學第一附屬醫院,推出業內首個心臟磁共振多模態診斷智能體BAAI Cardiac Agent。該智能體採用先進Agent技術,實現心臟磁共振影像全流程自動化處理,標誌着這一複雜領域正式進入自動化時代。
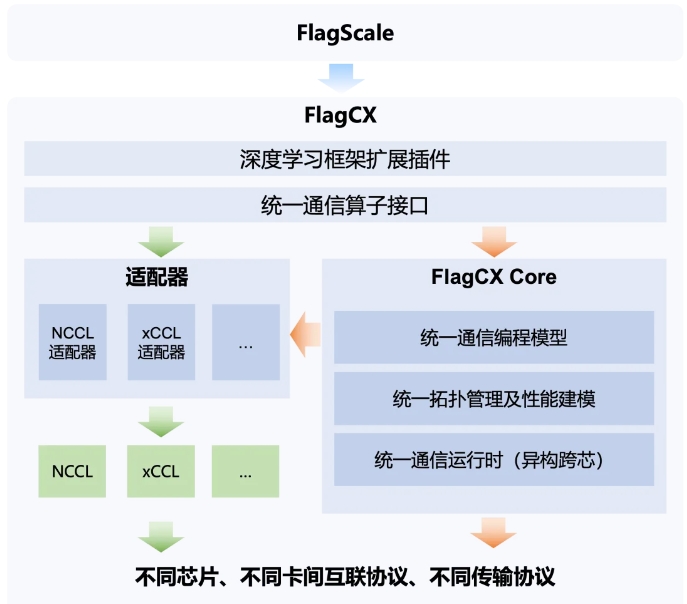
北京智源人工智能研究院(BAAI)近日宣佈,已聯合生態合作伙伴構建並開源了異構統一通信庫FlagCX,旨在解決多元算力時代通信庫面臨的挑戰,填補多元算力開源軟件棧的重要空白。這一舉措響應了國家有關部門組織的“清朗·網絡平臺算法典型問題治理”專項行動,體現了算法導向正確、公平公正、公開透明等重要原則。
北京智源人工智能研究院(BAAI)近日宣佈推出一款創新的3D生成模型See3D,該模型能夠利用大規模無標註的互聯網視頻進行學習。這一技術突破標誌着向“See Video, Get3D”的理念邁進了重要一步。See3D模型不依賴於傳統的相機參數,而是採用視覺條件技術,僅通過視頻中的視覺線索生成相機方向可控且幾何一致的多視角圖像。這種方法避免了昂貴的3D或相機標註的需求,能夠高效地從互聯網視頻中學習3D先驗。
北京智源人工智能研究院(BAAI)近日宣佈推出了一款全新的全能視覺生成模型OmniGen,標誌着圖像生成領域的一項重大突破。OmniGen模型以其統一性、簡單性和跨任務知識遷移能力而著稱,能夠在單一框架內處理多種圖像生成任務,包括文生圖、圖像編輯、主題驅動生成和視覺條件生成等。此外,OmniGen還能夠處理一些經典的計算機視覺任務,如圖像去噪和邊緣檢測,通過將這些任務轉換爲圖像生成任務來實現。
ekacare
Parrotlet-e是一款先進的多語言醫學嵌入模型,專門針對印度各語言中的醫學術語進行優化。它基於BAAI/bge-m3進行微調,在超過1800萬對多語言醫學術語對上進行訓練,支持12種印度語言和英語,對臨床文檔中的縮寫、拼寫變體和口語表達具有很強的魯棒性。
BAAI
Emu3.5是北京智源人工智能研究院開發的原生多模態模型,能夠跨視覺和語言聯合預測下一狀態,實現連貫的世界建模和生成。通過端到端預訓練和大規模強化學習後訓練,在多模態任務中展現出卓越性能。
Emu3.5是由北京智源人工智能研究院(BAAI)開發的原生多模態模型,能夠跨視覺和語言聯合預測下一狀態,實現連貫的世界建模與生成,在多模態任務中表現卓越。
bortunac
本模型是BAAI/bge-reranker-v2-m3的GGUF量化版本,使用Q4_K_M量化方法。它是一個多語言重排序模型,主要用於文本檢索中的結果重排序任務,能夠提升檢索結果的相關性。
MagicalAlchemist
BGE-M3是由BAAI開發的多功能文本嵌入模型,支持多語言、多粒度、多功能的文本表示學習,能夠同時處理稠密檢索、稀疏檢索和多向量檢索等多種檢索模式。
bartowski
這是BAAI的RoboBrain2.0-7B模型的量化版本,通過llama.cpp進行量化處理,提供多種量化類型以適應不同硬件需求。
BGE-Code-v1是一個基於LLM的代碼嵌入模型,支持代碼檢索、文本檢索和多語言檢索,在代碼檢索和文本檢索任務中表現出色。
foochun
這是一個從BAAI/bge-reranker-base微調而來的交叉編碼器模型,用於文本對評分,適用於文本重排序和語義搜索任務。
shuyuej
這是BAAI/bge-multilingual-gemma2模型的4位GPTQ量化版本,支持多語言文本嵌入任務。
datasocietyco
這是一個從BAAI/bge-base-en-v1.5微調而來的sentence-transformers模型,能將句子和段落映射到768維的密集向量空間。
mradermacher
這是BAAI/bge-large-zh-v1.5模型的加權/矩陣量化版本,提供多種量化選項,適用於不同需求場景。
BAAI/bge-large-zh-v1.5是一箇中文句子轉換器模型,主要用於特徵提取和句子相似度計算。
sabafallah
基於BAAI/bge-reranker-base模型轉換的GGUF格式重排序模型,支持中英文文本排序任務
pyarn
該模型是通過ggml.ai的GGUF-my-repo空間,使用llama.cpp從BAAI/bge-reranker-v2-m3轉換而來的GGUF格式模型,主要用於文本分類任務。
本模型是基於BAAI/bge-reranker-v2-m3轉換的GGUF格式模型,用於文本排序任務,支持多語言。
iris49
這是一個基於BAAI/bge-base-en-v1.5微調的句子轉換器模型,專為3GPP相關技術文檔的問答系統優化,能夠將文本映射到768維向量空間。
BlackBeenie
這是一個從BAAI/bge-m3微調而來的sentence-transformers模型,用於將句子和段落映射到1024維稠密向量空間,支持語義文本相似度、語義搜索等任務。
tinybiggames
該模型是通過GGUF-my-repo從BAAI/bge-m3轉換而來的GGUF格式模型,主要用於句子相似度計算和特徵提取。
pqnet
這是一個基於BAAI/bge-reranker-v2-m3模型轉換的GGUF格式文本排序模型,支持多語言文本嵌入推理。
sayed0am
這是BAAI/bge-m3模型的阿拉伯語精簡版本,保留了原模型約98%的質量,同時內存佔用更小。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)