在2026年達沃斯論壇上,DeepMind CEO哈薩比斯指出,中國AI技術已接近西方,差距縮小至約6個月。他特別肯定國產模型DeepSeek R1,稱其性能令人印象深刻,曾引發硅谷震動。
中國AI模型發展迅速,Deepseek R1等創新引發全球關注。阿里巴巴Qwen模型家族表現突出,中國開放權重AI生態系統規模遠超預期,在分發和應用方面已超越美國競爭對手。
聖誕節當天,邊緣AI初創公司Liquid AI發佈開源模型LFM2-2.6B-Exp,僅26億參數,卻在多項基準測試中表現優異,指令跟隨能力甚至超越數百億參數的DeepSeek R1-0528,被贊爲“最強3B級模型”。該模型基於第二代LFM2基礎模型,通過純強化學習實現實驗性突破。
Jan團隊發佈300億參數多模態大模型Jan-v2-VL-Max,專爲長週期、高穩定性自動化任務設計,性能超越谷歌Gemini2.5Pro與DeepSeek R1。該模型重點解決多步任務中的“誤差累積”和“失焦”問題,爲開源智能體生態提供強大支持。
DeepSeek R1-0528 是一款開源大模型,性能媲美 OpenAI o3 模型。
基於DeepSeek R1和V3模型的瀏覽器側邊欄AI工具,提供問答、創作、翻譯等功能
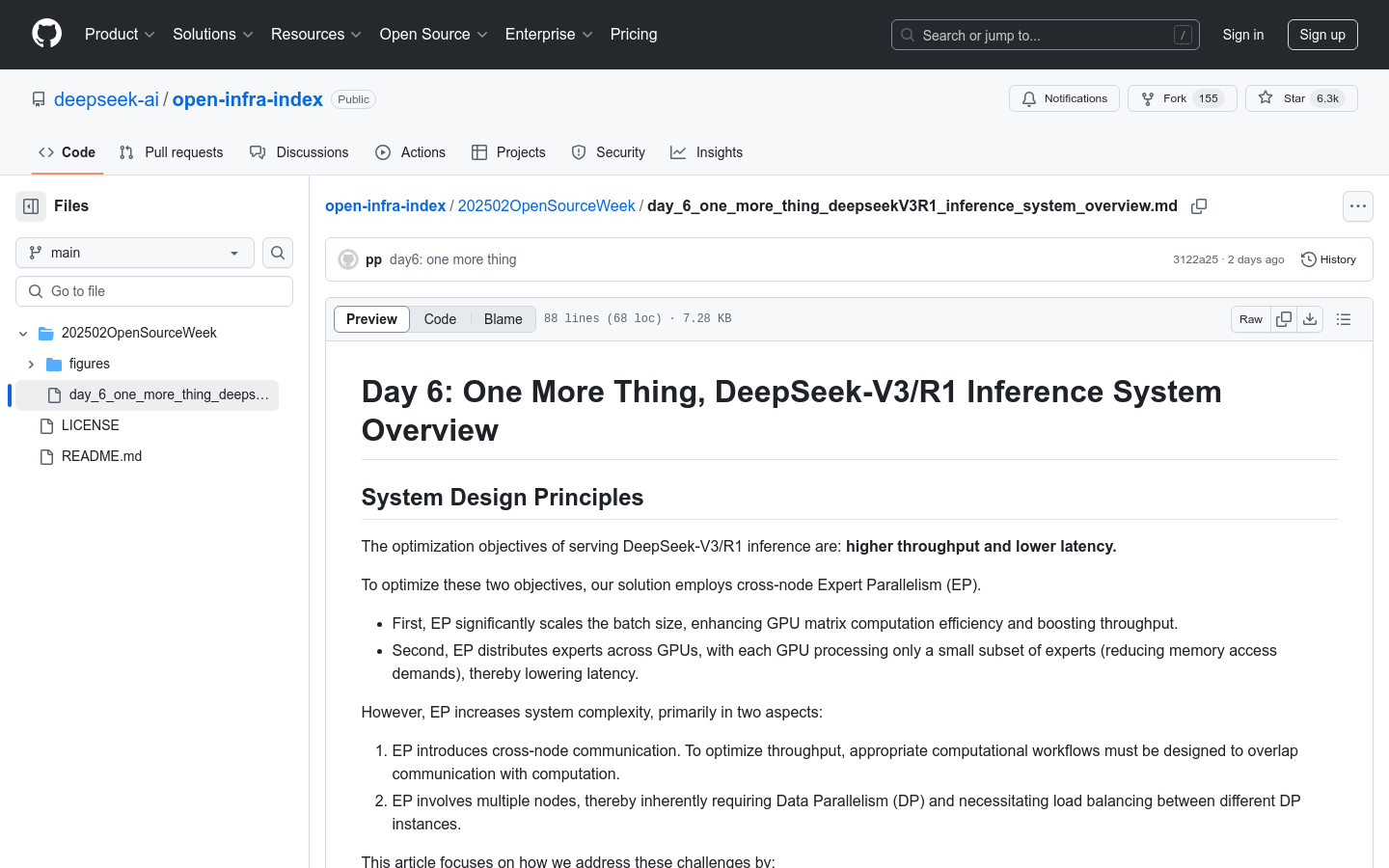
DeepSeek-V3/R1 推理系統是一個高性能的分佈式推理架構,專為大規模 AI 模型優化設計。
一個支持DeepSeek R1的AI驅動研究助手,結合搜索引擎、網絡爬蟲和大型語言模型進行深度研究。
Google
$0.49
輸入tokens/百萬
$2.1
輸出tokens/百萬
1k
上下文長度
Openai
$2.8
$11.2
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$6
$24
256
$4
$16
Baidu
128
Bytedance
$1.2
$3.6
4
$2
Moonshot
$0.8
$10.5
nvidia
NVIDIA DeepSeek R1 FP4 v2是基於DeepSeek AI的DeepSeek R1模型進行FP4量化的文本生成模型,採用優化的Transformer架構,可用於商業和非商業用途。該模型通過TensorRT Model Optimizer進行量化,相比FP8版本顯著減少了磁盤大小和GPU內存需求。
NVIDIA DeepSeek-R1-0528-FP4 v2是DeepSeek R1 0528模型的量化版本,採用優化的Transformer架構,是一個自迴歸語言模型。通過FP4量化優化,減少了磁盤大小和GPU內存需求,同時保持較高推理效率。
NVIDIA DeepSeek-R1-0528-FP4 是 DeepSeek R1 0528 模型的量化版本,採用優化的 Transformer 架構,權重和激活值量化為 FP4 數據類型,顯著減少磁盤大小和 GPU 內存需求,支持 TensorRT-LLM 推理引擎實現高效推理。
DeepSeek AI 公司的 DeepSeek R1 0528 模型的量化版本,基於優化的 Transformer 架構的自迴歸語言模型,可用於商業和非商業用途。
Sci-fi-vy
DeepSeek-R1-0528是DeepSeek R1系列的小版本升級模型,通過增加計算資源和算法優化顯著提升了推理深度和能力,在數學、編程等多個基準測試中表現出色。
cognitivecomputations
DeepSeek R1 0528的AWQ量化模型,支持使用vLLM在8塊80GB GPU上以全上下文長度運行。
QuixiAI
DeepSeek-R1-0528-AWQ 是 DeepSeek R1 0528 的 AWQ 量化版本,通過量化技術提升了模型運行效率,修復了代碼問題,提供更穩定的服務。
DeepSeek-R1-0528是DeepSeek R1模型的小版本升級,通過增加計算資源和算法優化顯著提升了推理能力,在數學、編程和通用邏輯等多個基準評估中表現出色。
ubergarm
DeepSeek - R1T - Chimera是一個高質量的大語言模型,通過ik_llama.cpp提供的先進量化方案,在保持性能的同時顯著減少內存佔用。
Nexesenex
Hexagon Purple V2是一個基於Smartracks的三級標準合併模型,包含Deepseek Distill R1、Nemotron和Tulu能力,通過多模型合併優化性能。
qihoo360
Tiny-R1-32B-Preview 是一個基於 Deepseek-R1-Distill-Qwen-32B 的推理模型,專注於數學、代碼和科學領域,性能接近完整版 R1 模型。
suayptalha
DeepSeek-R1-Distill-Llama-3B 是基於 Llama-3.2-3B 模型,使用 R1-Distill-SFT 數據集對 DeepSeek-R1 進行蒸餾得到的版本,具備文本生成能力。
NVIDIA DeepSeek R1 FP4 模型是 DeepSeek AI 的 DeepSeek R1 模型的量化版本,使用優化 Transformer 架構的自迴歸語言模型。該模型通過 FP4 量化技術將參數位數從 8 位減少到 4 位,使磁盤大小和 GPU 內存需求減少約 1.6 倍,同時保持較高的精度性能。
DeepSeek R1模型的FP4量化版本,採用優化後的Transformer架構實現高效文本生成
duxx
本模型是基於DeepSeek-R1-Distill-Qwen-1.5B在土耳其語-R1數據集上微調的版本,主要用於土耳其語相關推理任務。
lightblue
這是DeepSeek R1模型的日語版本,專門針對日語推理任務進行微調,能夠可靠且準確地以日語響應提示。
DeepSeek R1模型的AWQ量化版本,優化了float16溢出問題,支持高效推理部署
一個基於Node.js的Deepseek R1語言模型MCP服務器實現,支持8192令牌上下文窗口,提供穩定的Claude Desktop集成和模型參數配置。
Deepseek R1的MCP服務器實現,支持Node.js環境,提供強大的語言模型推理服務。
Deepseek R1的MCP服務器實現,支持與Claude Desktop集成,提供強大的語言模型推理服務。
一個利用Deepseek R1模型的思維鏈進行推理的MCP服務工具,支持在Claude Desktop等客戶端中使用。
 Safetensors
Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)