倫敦高等法院裁定Stable Diffusion訓練AI模型不構成版權侵權。Getty Images曾指控其抓取數百萬版權照片威脅創意產業,但最終放棄主要訴求。案件焦點在於使用版權圖像訓練AI是否侵權,裁決對AI開發與版權平衡具重要意義。
英國高等法院駁回Getty Images對Stability AI的版權訴訟,成爲生成式AI領域重要判例。案件核心爭議在於使用受版權圖片訓練AI模型是否侵權。Getty指控對方未經授權抓取其數百萬照片訓練Stable Diffusion模型,稱此舉威脅創意產業生存。目前案件仍在推進中。
英國法院就Getty Images訴Stability AI案作出裁決:Stability AI的圖像生成模型使用Getty商標構成侵權,但未支持Getty的版權侵權主張,因被告未存儲或複製受版權作品。
人工智能公司Perplexity與Getty Images達成多年圖片授權協議,將在其AI搜索工具中使用Getty的圖片。這標誌着Perplexity從過去因內容抓取和抄襲爭議(如被指控盜用Getty圖片)向建立正式合法內容合作的重要戰略轉變。
免費AI圖像編輯器和生成器,由Nano Banana AI驅動,功能強大無限制。
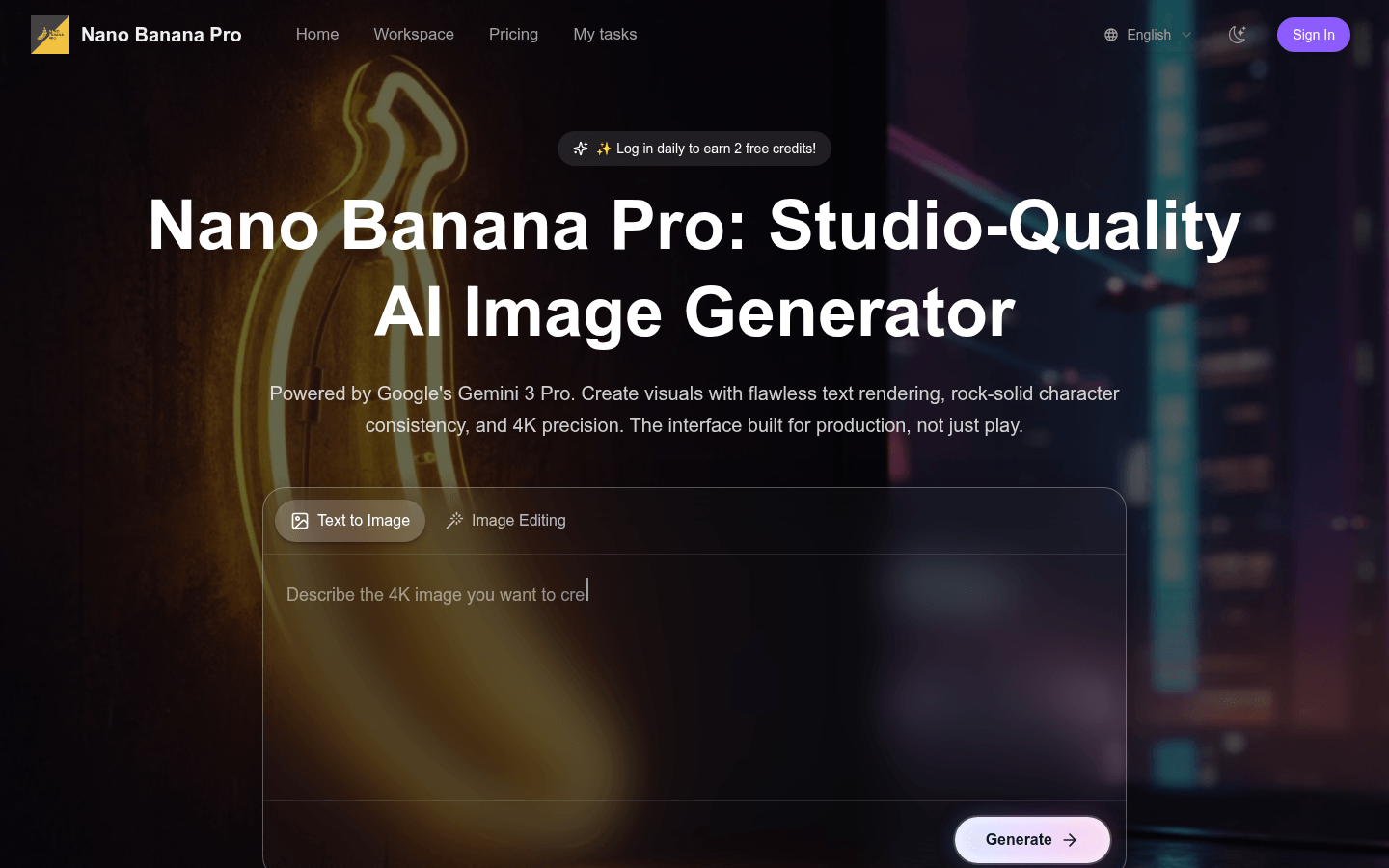
基於Gemini 3 Pro Image的AI圖像生成器,支持文本渲染和4K畫質
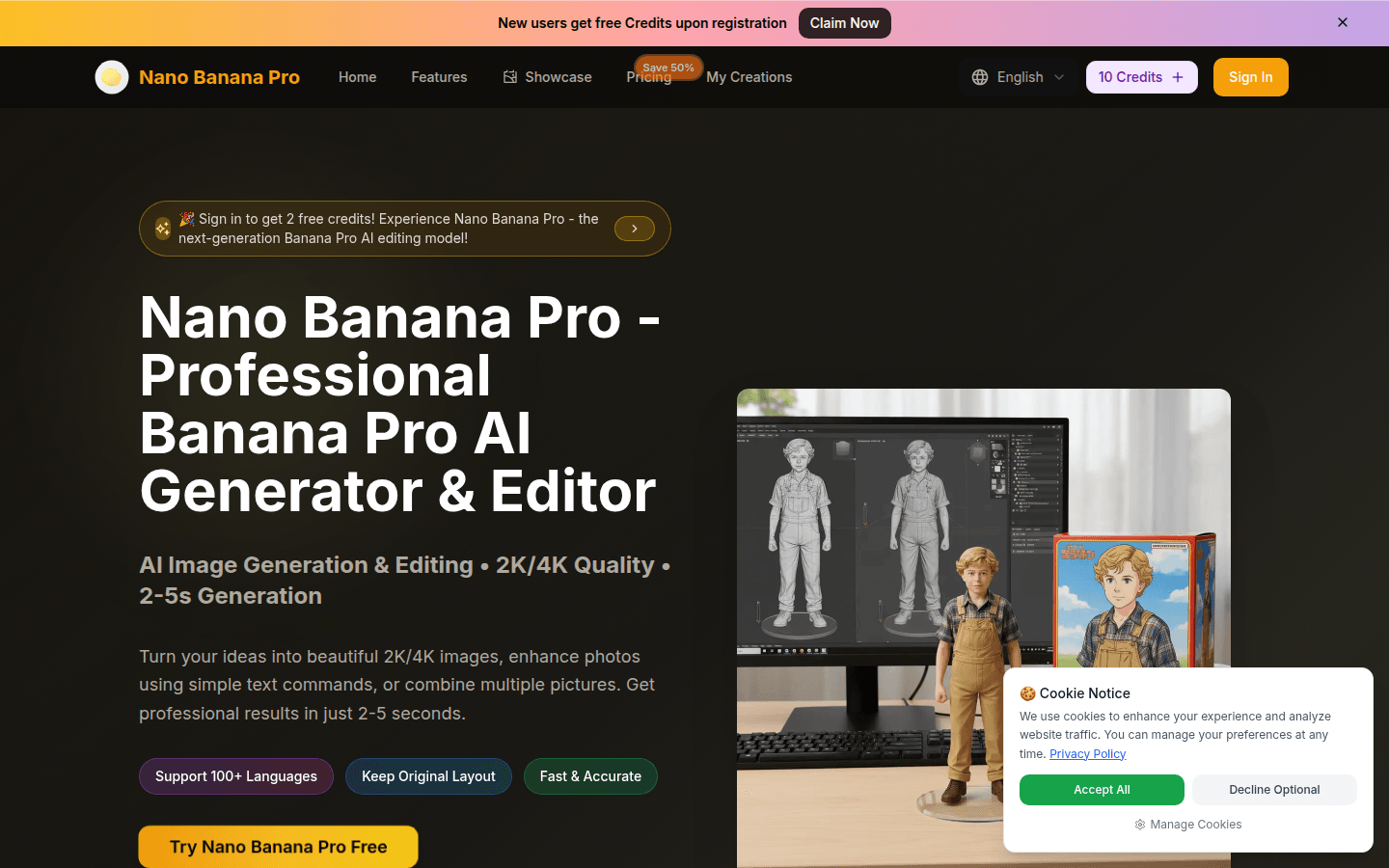
專業AI圖像生成與編輯器,2-5秒產出2K/4K高質量圖像,支持多語言
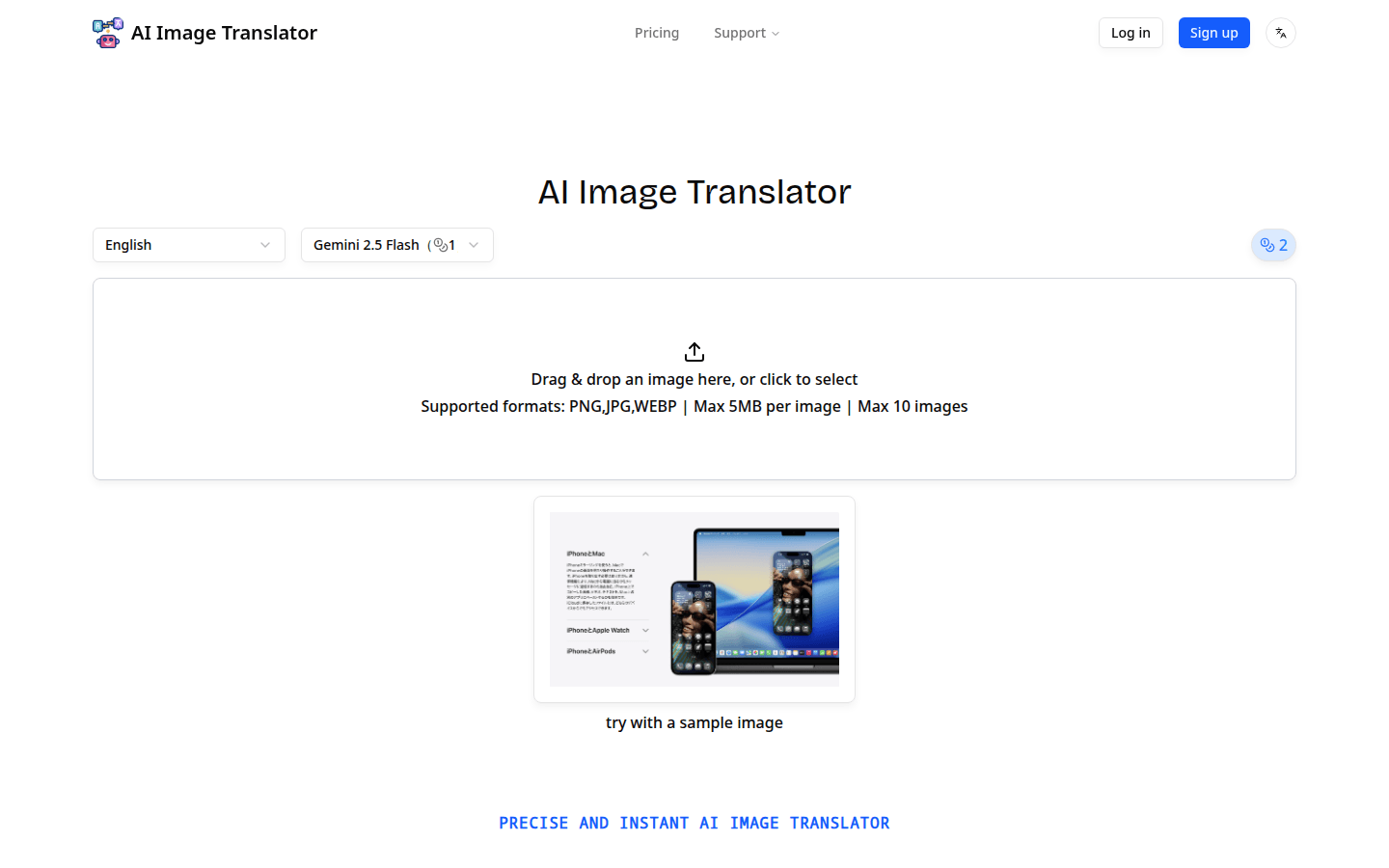
精準即時的AI圖像翻譯器,支持100種語言,操作高效
Tesslate
WEBGEN DEVSTRAL IMAGES 是一個專注於網頁生成的人工智能模型,能夠利用 HTML、CSS、JS 和 Tailwind 技術生成單頁式網頁。該項目基於自定義模板進行訓練,採用監督微調方法,使用 GPT-OSS-120B 生成的數據集進行訓練。
calcuis
Qwen Image Edit Plus GGUF 是一個基於 Qwen 模型的圖像編輯項目,提供多種運行方式,支持圖像編輯和生成任務。該項目通過 GGUF 格式優化了模型部署和運行效率。
gtmepm
simpletuner-lora 是一個基於 stabilityai/stable-diffusion-3.5-medium 的 LyCORIS 適配器,專門用於文生圖等圖像生成任務。該模型通過 LoRA 微調技術實現,主要使用驗證提示為'A photo-realistic image of a cat'進行訓練。
Immac
NetaYume Lumina Image 2.0 是一個文本到圖像的擴散模型,經過GGUF格式量化處理,能夠將文本描述轉換為圖像。該模型經過優化,在保持生成質量的同時減少了內存使用和提升了性能。
birder-project
採用RoPE的ViT圖像分類模型,經過CAPI預訓練和ImageNet-21K微調,適用於圖像分類和檢測任務。
gordon-0115
一個實驗性的自然語言到3D模型生成流程,基於改進的預訓練多視角擴散模型
naver-ai
一個輕量級的RDNet圖像分類模型,在ImageNet-1k數據集上訓練,參數量24M,top-1準確率82.8%。
eduardo-bolognini
這是一個託管在Hugging Face Hub上的transformers模型,具體功能和用途尚未明確說明。
saurabhati
VMamba 是一個基於雙向狀態空間模型的視覺模型,專為圖像分類任務設計,在 ImageNet 數據集上微調。
這是一個託管在Hugging Face Hub上的transformers模型,具體功能和用途需要進一步補充信息
xwen99
這是一個基於ImageNet-1k數據集訓練的KL16變分自編碼器(VAE)模型,用於圖像到圖像的轉換任務。
dima806
基於Vision Transformer架構的圖像分類模型,在ImageNet-21k數據集上預訓練,適用於多類別圖像分類任務
microsoft
TRELLIS Image Large是一個大型3D生成模型TRELLIS的圖像條件版本,能夠依據輸入圖像生成3D內容。
imagepipeline
FLUX.1-dev是一個基於文生圖技術的超寫實風格圖像生成模型,支持LoRA微調,適用於圖像處理管線。
FLUX.1-dev 是一個基於 diffusers 庫的圖像生成模型,專注於文生圖任務,支持超現實風格和動漫風格的圖像生成。
premanthcharan
結合視覺變換器(ViT)與自然語言處理的圖像描述生成模型,能夠自動為輸入圖像生成自然語言描述
trollek
這是一個基於h2oai/h2o-danube3-500m-base微調的圖像提示生成模型,專門用於將簡短的自然語言描述轉換為詳細、高質量的圖像生成提示詞。支持多種風格輸出,包括詳細描述、Danbooru標籤風格和混合風格。
adamdad
KAT是一種採用分組有理科爾莫戈羅夫-阿諾德網絡(GR-KAN)替代傳統Transformer中通道混合器的新型視覺模型,在ImageNet-1k數據集上訓練。
yayayaaa
基於Florence-2-large-ft模型在imageinwords數據集上微調,專注於生成更詳細的圖片描述
Alpiyildo
基於ViT架構的面部表情識別模型,在imagefolder數據集上微調,準確率達91.77%
一個基於FAL AI的Logo生成服務器,提供圖像生成、背景去除和自動縮放功能。
基於即夢AI的圖像生成服務,專為Cursor IDE設計,實現文本描述到圖像的生成與保存。
一個提供圖像獲取和處理功能的MCP服務器,支持從URL、本地路徑和numpy數組加載圖像,並返回base64編碼的字符串和MIME類型。
一個支持獲取圖片尺寸和壓縮圖片的MCP服務工具
MCP圖像提取轉換服務,為AI助手提供本地/網絡圖像處理和base64編碼功能
一個基於MCP協議的圖像處理服務器,通過自然語言指令實現專業級圖片編輯功能
一個基於TypeScript的MCP服務器,使用OpenAI的DALL-E 3模型根據文本提示生成圖像。
該項目是一個集成Stable Diffusion圖像生成功能的MCP服務器,為AI代理提供圖像生成服務,支持通過MCP協議或直接API調用生成圖像,幷包含開發調試工具。
一個支持圖片下載和處理的MCP服務器,提供批量下載、格式轉換、尺寸調整和壓縮等功能
一個基於GPT-4o-mini模型的圖像分析MCP服務器,可處理URL或本地路徑的圖像內容分析
一個基於Together AI和Replicate的圖像生成MCP服務
Image Gen MCP Server是一個通用AI圖像生成服務,通過Model Context Protocol(MCP)標準協議為各類LLM聊天機器人提供跨平臺、多模型的圖像生成能力,支持OpenAI和Google的多種圖像模型,實現文本對話到可視化內容的無縫轉換。
一個基於MCP協議的圖像下載與優化服務
該項目實現了一個MCP服務器,通過OpenAI的gpt-image-1模型提供圖像生成和編輯功能,支持文本描述生成圖像、基於參考圖像編輯或修復圖像,並可將結果保存到本地。
Grok AI圖像生成MCP服務器項目,支持通過Docker容器化部署,提供多圖生成與多種返回格式支持。
一個基於Replicate Flux模型的圖像生成MCP服務器,為Claude Desktop提供圖像生成能力
一個基於Sharp庫的圖片處理MCP服務,提供調整尺寸、格式轉換、裁剪、旋轉和獲取圖片信息等功能
一個基於Model Context Protocol(MCP)的輕量級服務器,專為圖像處理和雲上傳設計,支持調整大小、轉換、優化及上傳到多種雲存儲服務,適用於AI助手和自動化工作流。
基於Ideogram API的圖片生成MCP服務器
一個基於xAI Grok API的MCP服務器,提供AI圖像分析功能,支持URL和本地文件的圖像描述、元數據提取和OCR文字識別
 Diffusers
Diffusers%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)