在 AI 時代,大型語言模型(LLM)就像武林祕籍,其訓練過程耗費巨大算力、數據,就像閉關修煉多年的武林高手。而開源模型的發佈,就像高手將祕籍公之於衆,但會附帶一些許可證(如 Apache2.0和 LLaMA2社區許可證)來保護其知識產權(IP)。然而,江湖險惡,總有“套殼”事件發生。一些開發者聲稱自己訓練了新的 LLM,實際上卻是在其他基礎模型(如 Llama-2和 MiniCPM-V)上進行包裝或微調。 這就好像偷學了別人的武功,卻對外宣稱是自己原創的。爲了防止這種情況發生,模型所有者和第三方迫
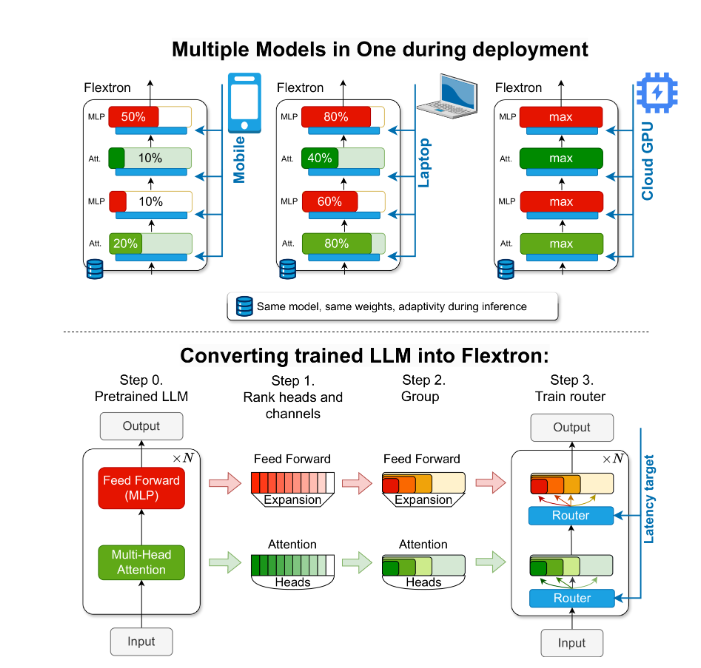
在AI領域,大型語言模型(LLMs)展現出了極高的語言理解和生成能力,如GPT-3和Llama-2等。然而,這些模型的龐大參數量對訓練和部署提出了高資源需求的挑戰,傳統的解決辦法是訓練多版本模型以適應不同計算環境,但這種做法效率低下。爲此,NVIDIA和德克薩斯大學奧斯汀分校提出Flextron框架,一種支持無需額外微調的靈活模型架構和優化方法。Flextron能根據特定的延遲和準確性需求,在推理過程中動態調整模型部署,顯著減少對多個模型變體的依賴。通過樣本高效訓練方法和先進的路由算法,Flextron將預訓練的LLMs轉化爲能夠適應各種部署場景的彈性模型,節省計算資源和時間。對比其他最先進的彈性網絡,Flextron在效率和準確性上都有出色表現,並通過彈性多頭注意力層進一步優化資源利用,特別適合資源有限的計算環境。
"美國國防部最近啓動了一項賞金計劃,旨在尋找人工智能模型中的法律偏見。該計劃要求參與者從Meta的開源LLama-270B模型中提取明顯的偏見例證。通過這一舉措,五角大樓希望改"
["Colossal-AI 團隊以低成本構建了性能卓越的中文 LLaMA-2 模型","中文版 LLaMA-2 在多個評測榜單中表現優異","Colossal-AI 開源了完整的訓練流程、代碼及權重","Colossal-AI 提供了評估體系框架 ColossalEval","Colossal-AI 的方案可用於構建任意垂類領域的大模型"]
Baidu
-
輸入tokens/百萬
輸出tokens/百萬
32
上下文長度
Alibaba
$0.5
Google
$0.7
$1.4
131
Tencent
$4
$12
28
Deepseek
$1
8
01-ai
4
200
Baichuan
Bytedance
$5
$9
256
MerantixMomentum
ACIP項目提供的Llama-2-13b可壓縮版本,支持動態調整壓縮率
Mungert
Llama 2是由Meta開發的7B參數規模的大語言模型,提供多種量化版本以適應不同硬件需求。
SURESHBEEKHANI
基於Llama-2-7b微調的醫學對話模型,用於回答醫學相關問題並提供詳細知識。
matrixportalx
這是一個基於Meta的Llama-2-7b-chat-hf模型轉換而來的GGUF格式版本,採用Q4_K_M量化技術,適用於llama.cpp推理框架,支持高效的文本生成和對話任務。
matrixportal
Meta發佈的Llama 2系列7B參數聊天模型GGUF量化版本,適用於本地部署和推理
diffusionfamily
基於Llama-2-7b微調的擴散語言模型
miulab
LLaMA-2 Reward Model是基於LLaMA-2-7B架構訓練的獎勵模型,通過模型融合技術為獎勵模型賦予領域知識。該模型在argilla/ultrafeedback-binarized-preferences-cleaned數據集上訓練,專門用於文本分類任務,具有重要的研究和應用價值。
tanusrich
基於LLaMA-2-7b微調的心理健康輔助對話模型,提供共情支持和非評判性心理幫助
inceptionai
Jais Adapted 13B是基於Llama-2架構的雙語(阿拉伯語-英語)大語言模型,通過自適應預訓練增強阿拉伯語能力
Jais系列是基於Llama-2架構的雙語大語言模型,專為阿拉伯語優化同時具備強大英語能力。本模型為700億參數規模的阿拉伯語自適應版本,支持4,096上下文長度。
Jais系列是專精阿拉伯語處理的雙語大語言模型,基於Llama-2架構進行阿拉伯語適配預訓練
Jais系列是專為阿拉伯語優化的英阿雙語大語言模型,基於Llama-2架構進行自適應預訓練,具備強大的雙語處理能力。
varma007ut
基於Llama-2-7b微調的印度法律專用對話模型,專注於提供印度法律相關問題的回答。
HiTZ
Latxa是基於LLaMA-2架構的巴斯克語大語言模型,專為低資源語言設計,在42億token的巴斯克語料庫上訓練
NikolayKozloff
這是一個基於Llama-2-7b架構的烏克蘭語和英語語言模型,已轉換為GGUF格式,適用於llama.cpp框架。
sudipto-ducs
InLegalLLaMA是基於Llama-2-7B在印度法律和科學數據集上微調的大語言模型,專門針對法律文本生成任務進行優化,適用於印度法律領域的應用場景。
tartuNLP
Llama-2-7b-烏克蘭語版是一個支持烏克蘭語和英語的雙語預訓練模型,基於Llama-2-7b繼續預訓練,使用了來自CulturaX的50億token數據。
RedHatAI
這是一個基於Meta的Llama 2 7B模型進行微調的算術推理模型,專門針對GSM8K數學問題數據集進行了優化,在數學推理任務上表現出色。
Bohanlu
基於臺語-Llama-2系列模型構建,專注於臺灣閩南語與繁體中文、英語之間的翻譯任務。
ChrisPuzzo
基於Llama2-7B-Chat模型微調的隱私政策問答與摘要工具
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)