近日,NVIDIA正式宣佈與Meta建立一項爲期多年、跨世代的戰略合作伙伴關係。根據雙方達成的協議內容,Meta計劃在其超大規模的AI數據中心內部署數百萬顆NVIDIA的Blackwell GPU,以及專爲智能體AI推理量身打造的下一代Rubin架構GPU,以強化其AI算力基礎。
英偉達發佈大模型微調指南,降低技術門檻,讓普通開發者也能在消費級設備上高效完成模型定製。該指南詳解如何在NVIDIA全系硬件上利用開源框架Unsloth實現專業級微調。Unsloth專爲NVIDIA GPU打造,優化訓練全流程,提升性能。
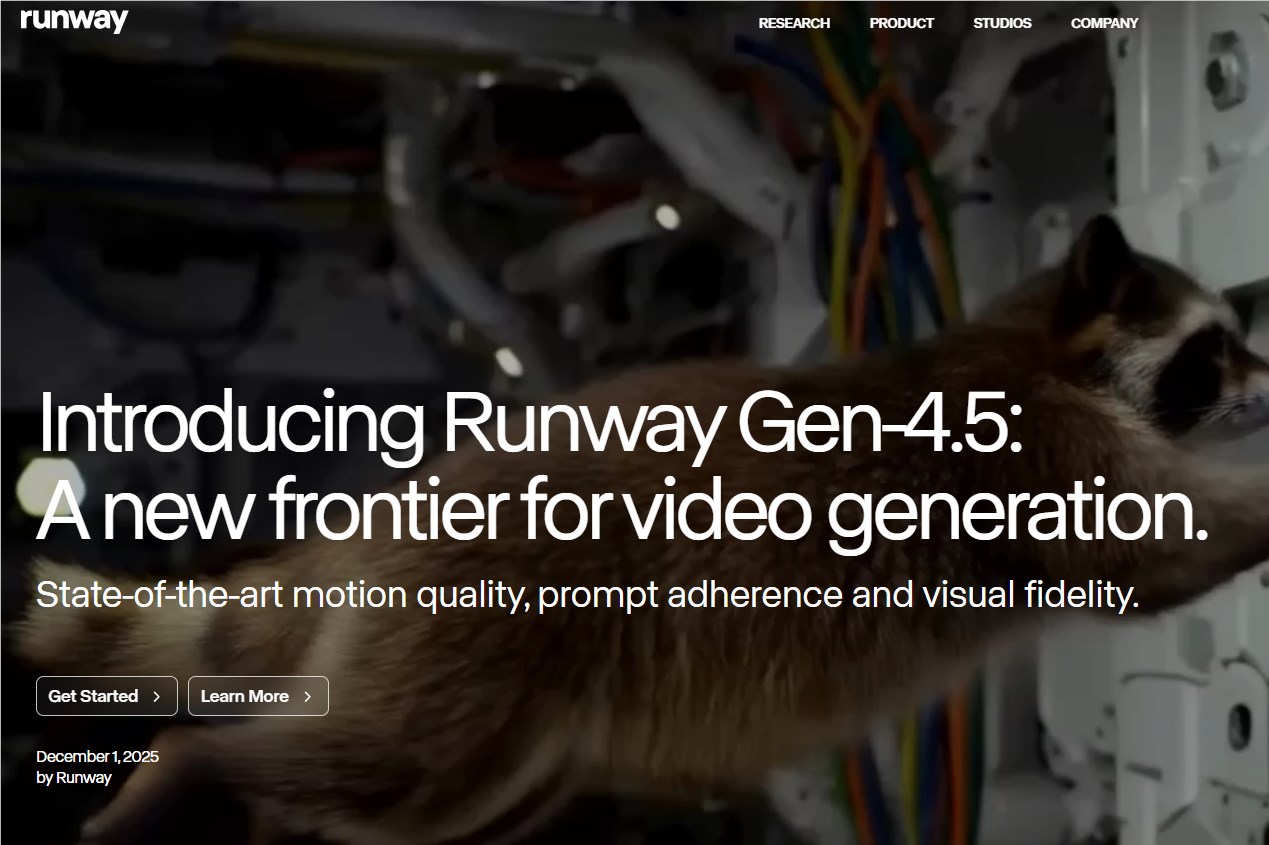
Runway發佈最新視頻生成模型Gen-4.5,專爲創作者、影視製作人和企業用戶設計,即將向所有訂閱層級開放。該模型在文本轉視頻基準測試中以1247分領先,超越谷歌Veo3等競品,成爲當前最強文生視頻模型。其卓越性能得益於先進的NVIDIA Hopper與Blackwell GPU平臺支持。
Runway發佈新一代視頻生成模型Gen-4.5,顯著提升視覺準確性與創意控制能力。用戶通過簡短文本提示即可生成高清動態視頻,支持複雜場景與生動角色。該模型基於Nvidia GPU進行訓練與推理,優化生成精度與風格表現。
NVIDIA® GeForce RTX™ 5090是迄今為止最強大的GeForce GPU,為遊戲玩家和創作者帶來變革性能力。
NVIDIA GPU上加速LLM推理的創新技術
NVIDIA H200 NVL GPU,為AI和HPC應用加速
NVIDIA深度學習教學套件,助力教育者融入GPU課程。
Openai
$2.8
輸入tokens/百萬
$11.2
輸出tokens/百萬
1k
上下文長度
-
Bytedance
$0.8
$2
128
Alibaba
$0.4
$8.75
$70
400
$1.75
$14
$0.35
64
$0.63
$3.15
131
$1.8
$5.4
16
Tencent
32
$17.5
$56
$0.7
$2.4
$9.6
Google
$0.14
$0.28
Qwen
Qwen3-VL-2B-Thinking是Qwen系列中最強大的視覺語言模型之一,採用GGUF格式權重,支持在CPU、NVIDIA GPU、Apple Silicon等設備上進行高效推理。該模型具備出色的多模態理解和推理能力,特別增強了視覺感知、空間理解和智能體交互功能。
TheStageAI
TheWhisper-Large-V3是OpenAI Whisper Large V3模型的高性能微調版本,由TheStage AI針對多平臺(NVIDIA GPU和Apple Silicon)的即時、低延遲和低功耗語音轉文本推理進行了優化。
RedHatAI
這是NVIDIA-Nemotron-Nano-9B-v2模型的FP8動態量化版本,通過將權重和激活量化為FP8數據類型實現優化,顯著減少磁盤大小和GPU內存需求約50%,同時保持出色的文本生成性能。
nvidia
NVIDIA Qwen2.5-VL-7B-Instruct-FP4是阿里巴巴Qwen2.5-VL-7B-Instruct模型的量化版本,採用優化的Transformer架構,支持多模態輸入(文本和圖像),適用於多種AI應用場景。該模型通過TensorRT Model Optimizer進行FP4量化,在NVIDIA GPU上提供高效的推理性能。
NVIDIA Qwen3-14B FP4模型是阿里巴巴Qwen3-14B模型的量化版本,採用FP4數據類型進行優化,通過TensorRT-LLM進行高效推理。該模型專為NVIDIA GPU加速系統設計,適用於AI Agent系統、聊天機器人、RAG系統等多種AI應用場景,支持全球範圍內的商業和非商業使用。
NVIDIA Qwen3-14B FP4 模型是阿里雲 Qwen3-14B 模型的量化版本,採用優化的 Transformer 架構,是一個自迴歸語言模型。該模型使用 TensorRT Model Optimizer 進行量化,將權重和激活量化為 FP4 數據類型,可在 NVIDIA GPU 加速系統上實現高效推理。
NVIDIA Qwen3-8B FP8 是阿里巴巴Qwen3-8B模型的量化版本,採用優化的Transformer架構,屬於自迴歸語言模型。該模型通過FP8量化技術優化,可在NVIDIA GPU上實現高效推理,支持商業和非商業用途。
jet-ai
Jet-Nemotron-4B是NVIDIA推出的高效混合架構語言模型,基於後神經架構搜索和JetBlock線性注意力模塊兩大核心創新構建,在性能上超越了Qwen3、Qwen2.5、Gemma3和Llama3.2等開源模型,同時在H100 GPU上實現了最高53.6倍的生成吞吐量加速。
ESM-2是NVIDIA基於TransformerEngine優化的蛋白質語言模型,能夠從氨基酸序列預測蛋白質3D結構。該模型採用掩碼語言建模目標訓練,在NVIDIA GPU上具有更快的訓練和推理速度。
NVIDIA DeepSeek R1 FP4 v2是基於DeepSeek AI的DeepSeek R1模型進行FP4量化的文本生成模型,採用優化的Transformer架構,可用於商業和非商業用途。該模型通過TensorRT Model Optimizer進行量化,相比FP8版本顯著減少了磁盤大小和GPU內存需求。
NVIDIA DeepSeek-R1-0528-FP4 v2是DeepSeek R1 0528模型的量化版本,採用優化的Transformer架構,是一個自迴歸語言模型。通過FP4量化優化,減少了磁盤大小和GPU內存需求,同時保持較高推理效率。
NVIDIA Qwen3-30B-A3B FP4模型是阿里雲Qwen3-30B-A3B模型的量化版本,採用優化的Transformer架構,是自迴歸語言模型。該模型使用TensorRT Model Optimizer進行FP4量化,將每個參數的比特數從16位減少到4位,使磁盤大小和GPU內存需求減少約3.3倍,同時保持較高的性能表現。
NVIDIA Qwen3-235B-A22B FP4模型是阿里雲Qwen3-235B-A22B模型的量化版本,採用優化的Transformer架構,是一種自迴歸語言模型。該模型通過FP4量化技術將參數從16位減少到4位,使磁盤大小和GPU內存需求減少約3.3倍,同時保持較高的準確性和性能。
NVIDIA Qwen3-235B-A22B FP8模型是阿里雲Qwen3-235B-A22B模型的量化版本,採用優化的Transformer架構,是一個自迴歸語言模型。該模型通過FP8量化技術顯著減少了磁盤空間和GPU內存需求,同時保持較高的推理精度,適用於各種AI應用場景。
NVIDIA DeepSeek-R1-0528-FP4 是 DeepSeek R1 0528 模型的量化版本,採用優化的 Transformer 架構,權重和激活值量化為 FP4 數據類型,顯著減少磁盤大小和 GPU 內存需求,支持 TensorRT-LLM 推理引擎實現高效推理。
NVIDIA DeepSeek R1 FP4 模型是 DeepSeek AI 的 DeepSeek R1 模型的量化版本,使用優化 Transformer 架構的自迴歸語言模型。該模型通過 FP4 量化技術將參數位數從 8 位減少到 4 位,使磁盤大小和 GPU 內存需求減少約 1.6 倍,同時保持較高的精度性能。
microsoft
Phi-3 Small是一個70億參數的輕量級前沿開源模型,針對NVIDIA GPU優化的ONNX版本,支持8K上下文長度,具備強推理能力。
用於Kubernetes集群中NVIDIA GPU硬件診斷的即時SRE診斷代理,通過MCP協議提供即時GPU硬件檢測和故障排查功能。
 Safetensors
Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)