Adobe與ChatGPT合作,用戶可通過對話直接編輯Photoshop、Acrobat等應用文件,用自然語言描述需求即可完成圖片和PDF設計,無需切換軟件。
Adobe在ChatGPT中集成Photoshop、Express和Acrobat,用戶可直接通過對話進行修圖、設計和PDF處理,無需切換應用。此舉結合了Adobe的創意工具與ChatGPT的便捷交互,降低了創作門檻。
Adobe宣佈與ChatGPT合作,將其Photoshop、Express和Acrobat的核心功能集成到AI平臺中。用戶可通過自然語言指令直接編輯圖像、修改PDF或製作動畫,實現AI驅動的專業工具操作。此舉旨在推進其“AI優先”戰略,吸引更多用戶,並標誌着Adobe產品工作流程的重大變革。
Kimi推出基於Google Nano Banana Pro模型的幻燈片生成器,提供48小時免費試用。核心功能“Agentic Slides”可自動將PDF、圖片等文檔轉換爲演示文稿,支持瀏覽器內直接編輯。
免費的 AI 視頻轉換為可編輯 PowerPoint 和 PDF 工具。
Uniqode免費二維碼生成器,可生成URL、PDF等二維碼,支持自定義。
快速將 PDF 文件轉換為 Markdown 格式,保留原始樣式。
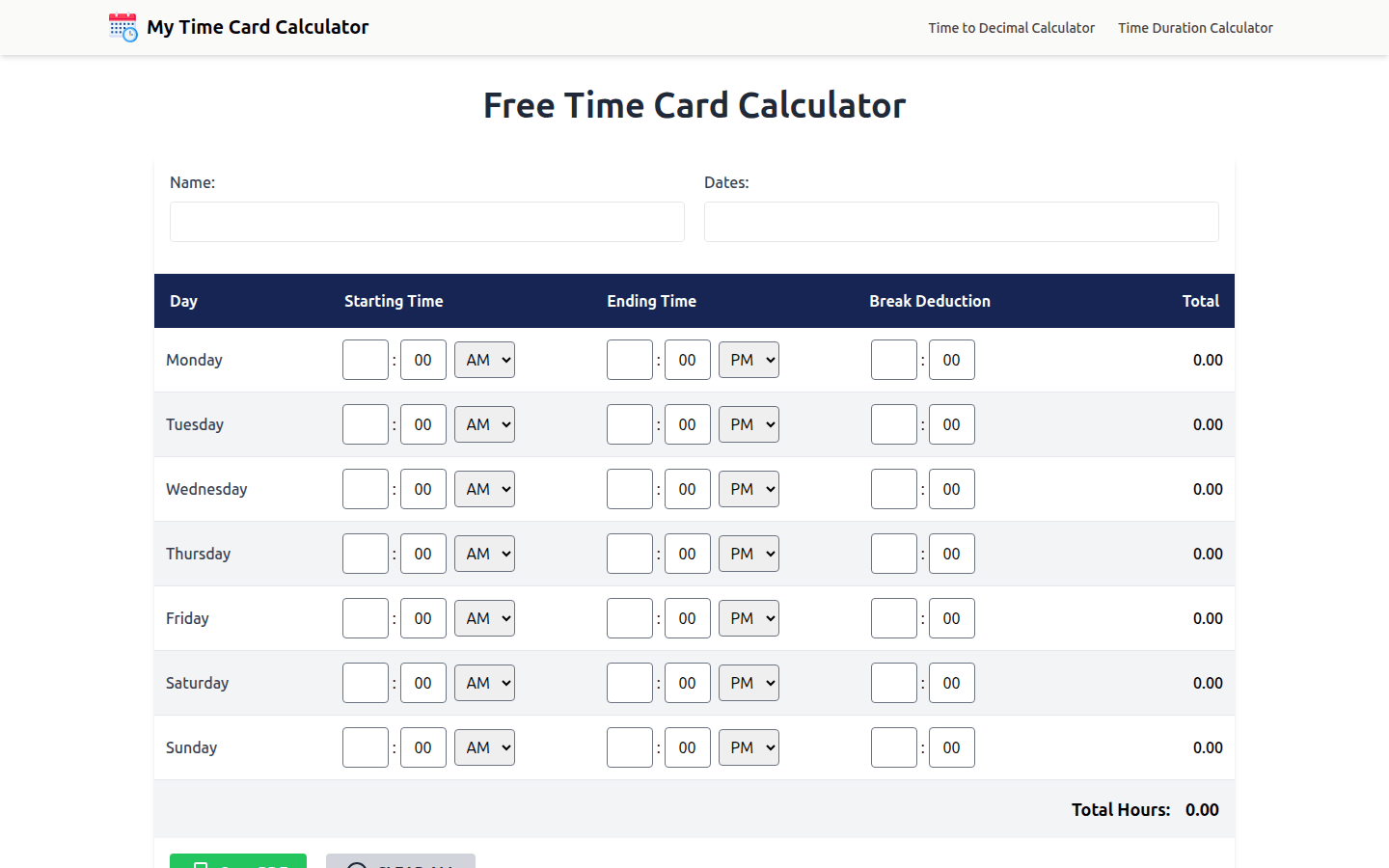
免費工時計算器,輕鬆計算工作時長、休息時間和每週總計,支持PDF下載。
TomoroAI
TomoroAI/tomoro-colqwen3-embed-4b是一款先進的ColPali風格多模態嵌入模型,能夠將文本查詢、視覺文檔(如圖像、PDF)或短視頻映射為對齊的多向量嵌入。該模型結合了Qwen3-VL-4B-Instruct和Qwen3-Embedding-4B的優勢,在ViDoRe基準測試中表現出色,同時顯著減少了嵌入佔用空間。
prithivMLmods
Chandra是一款高精度的OCR模型,能夠將圖像和PDF轉換為結構化輸出,如Markdown、HTML和JSON,同時保留詳細的佈局信息。支持40多種語言,擅長處理複雜的文檔元素。
noctrex
LightOnOCR-1B-1025的量化版本,專門用於圖像轉文本任務,在文檔理解、視覺語言處理等領域有廣泛應用。該模型支持多種歐洲語言,適用於OCR、PDF處理和表格識別等場景。
Mungert
Nanonets-OCR2-3B GGUF模型是專為文檔處理設計的強大工具,能夠將各類文檔智能轉換為結構化的Markdown格式,具備OCR、圖像轉文本、PDF轉Markdown以及視覺問答等多種先進識別和處理能力。
datalab-to
Chandra是一款先進的OCR模型,能夠從圖像和PDF中高精度提取文本並保留佈局信息。它支持Markdown、HTML和JSON格式輸出,在手寫體識別、表單重構、表格處理等方面表現出色,支持40多種語言。
echo840
MonkeyOCR是一款基於結構-識別-關係(SRR)三元範式的文檔解析模型,能夠高效處理PDF和圖像文檔,提取文本、公式、表格等結構化內容,支持中英文文檔解析。
Adun
olmOCR是一款基於Qwen2-VL-7B-Instruct微調的光學字符識別模型,專注於將PDF等圖像內容轉換為文本,並通過微調提升特定場景下的識別準確率。
apkonsta
專為國際財務報告準則(IFRS)PDF文檔優化的表格檢測模型,擅長處理無邊框表格
kitjesen
該模型能夠將PDF文檔轉換為Markdown格式,保持原始文檔排版結構,準確識別數學公式和表格。
shixuanleong
VisualHeist是一個目標檢測模型,專門用於從PDF文件中提取圖表、示意圖和表格,包括標題、頁眉和頁腳。
HongxuanLi
Nougat是基於Donut架構的視覺-語言模型,專為將科學類PDF轉錄為Markdown格式而設計。
hantian
一款閱讀順序預測模型,可將從PDF提取或通過OCR檢測的文本框轉換為可讀順序。
Xenova
Nougat是一個基於視覺的學術文檔理解模型,能夠將科學PDF圖像轉換為Markdown格式文本。
facebook
Nougat是基於Donut架構的視覺-語言模型,專為將科學PDF轉換為Markdown格式而設計。
Nougat是基於Donut架構的模型,專為將科學PDF轉錄為易用Markdown格式而訓練
shubh1608
基於圖像文件夾數據集訓練的OCR模型,用於PDF文檔的文本識別
impira
基於LayoutLM架構微調的文檔分類模型,專門用於處理PDF文檔特別是發票的分類任務
geralt
基於100多本機械/汽車類PDF書籍文本微調的蒸餾版GPT-2模型,專注於機械工程領域的文本生成任務
Markdownify是一個多功能文件轉換服務,支持將PDF、圖片、音頻等多種格式及網頁內容轉換為Markdown格式。
一個基於MarkItDown工具的MCP服務器,支持將PDF、PPT、Word等多種文件格式轉換為Markdown格式。
Nutrient DWS MCP Server是一個與Nutrient文檔Web服務處理器API集成的模型上下文協議服務器,為AI助手提供強大的PDF處理功能,包括數字簽名、文檔生成、編輯、OCR、水印、塗黑等操作。
MCP開發框架是一個用於創建與大語言模型交互自定義工具的強大框架,提供文件處理、網頁內容獲取等功能,支持PDF、Word、Excel等多種格式,具有智能識別、高效處理和內存優化等技術特點。
一個基於Python的MCP服務器,利用Pandoc提供強大的文檔轉換功能,支持多種格式間的轉換,如Markdown、DOCX、HTML、PDF等,適合與AI代理集成使用。
一個為Claude Desktop提供文檔操作功能的MCP服務器,支持Word、Excel和PDF文件的創建、編輯與格式轉換。
PDF內容提取服務
Rember MCP是一個官方協議服務,允許Claude創建閃卡,幫助用戶通過間隔重複複習來記憶內容。支持從聊天或PDF中生成閃卡,並提供API和桌面客戶端集成。
Markdownify MCP UTF-8增強版是一個支持多語言內容轉換的Markdown處理服務,優化了UTF-8編碼支持,提供PDF/圖片/音視頻/Office文檔等多種格式的Markdown轉換能力,並針對Windows系統進行了特別優化。
MCP開發框架是一個用於與大語言模型交互的強大工具集,提供文件處理(PDF/Word/Excel)、網頁內容獲取等功能,支持Cursor IDE擴展,具有智能文件識別、高效處理和內存優化等技術特點。
一個基於MCP協議的PDF轉PNG服務工具
該項目是一個基於FastMCP的USPTO專利數據訪問服務器,支持通過專利公共搜索API和開放數據門戶API獲取美國專利商標局的專利和專利申請數據,為Claude Desktop等MCP客戶端提供專利搜索、全文獲取、PDF下載和元數據查詢功能。
Ebook-MCP是一個基於模型上下文協議(MCP)的電子書處理服務器,支持EPUB和PDF格式,提供智能圖書管理、交互式閱讀體驗和學習輔助功能,實現與電子書的自然語言交互。
這是一個基於MCP協議的文檔生成服務器,支持創建DOCX和PDF格式的文檔,提供段落、表格和樣式設置功能,支持STDIO和HTTP兩種傳輸模式,幷包含會話管理功能。
MCP服務器PDF處理服務
Archive Agent 是一個智能文件索引工具,支持通過自然語言搜索和提問文件內容。它結合了AI搜索(RAG引擎)、自動OCR和MCP接口,能夠處理多種文件類型,包括文本、文檔、PDF和圖像。
Sci-Hub MCP服務是一個連接AI助手與Sci-Hub學術資源的橋樑,通過Model Context Protocol協議提供論文搜索、元數據獲取和PDF下載功能。
基於MCP的高性能PDF轉Markdown服務,支持批量處理和結構化輸出
一個通過MCP協議從AWS S3獲取PDF等數據的服務實現
一個支持MCP協議的PDF閱讀工具,通過MCP服務器提供read_pdf功能讀取PDF文檔,適用於Claude Desktop等MCP支持的AI工具。
 Transformers其他
Transformers其他%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)