OpenAI CEO Sam Altman透露,印度已成爲ChatGPT全球第二大市場,周活躍用戶達1億。爲適應印度市場,OpenAI推出低價版ChatGPT Go,並設立新德里辦事處,以搶佔年輕用戶市場。
OpenAI CEO Sam Altman 重金投資斯坦福教授李飛飛創立的AI公司World Labs,該公司已融資超1億美元,估值達10億美元量級,致力於開發具備人類感知能力的AI技術。
OpenAI CEO Sam Altman宣佈推出編程大模型GPT-5.3-Codex,該模型在技術指標和應用層面實現突破,推動AI輔助編程進入新階段。在SWE-Bench Pro評測中達到57%,在TerminalBench2.0和OSWorld評測中表現優異。
OpenAI CEO Sam Altman警告,AI代理的強大功能與便利性正誘使人類在安全措施不足時過度授權。他以自身爲例,承認曾決心限制權限,卻因“代理看起來很靠譜”而迅速反悔,賦予模型完全訪問權限。他擔憂這種盲目信任可能導致社會面臨嚴重風險。
使用Meta AI進行音頻分離,可通過文本、視覺或時間提示編輯音頻。
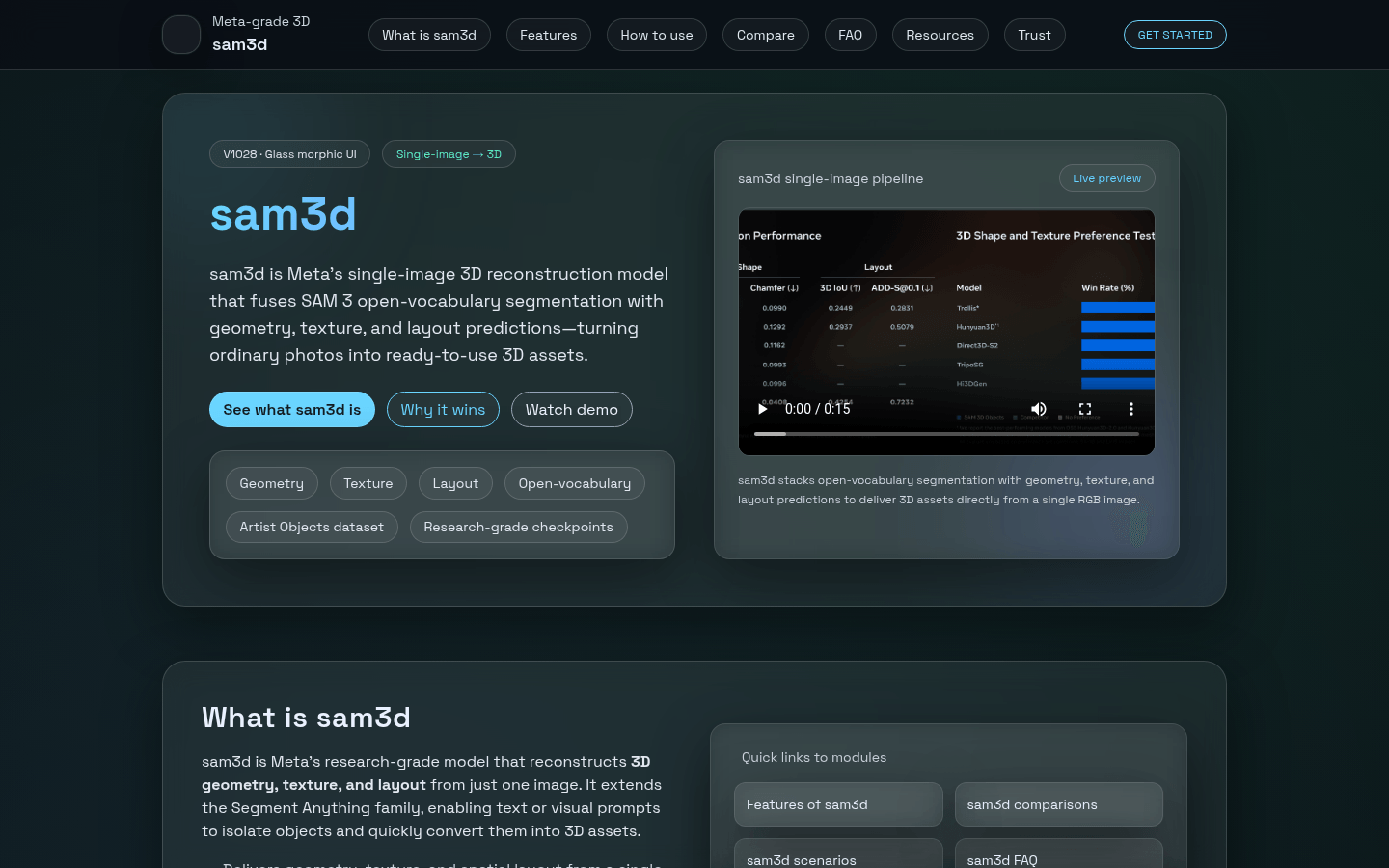
基於Meta的SAM 3D模型,可秒將單張圖像轉換成高質量3D模型。
SAM 3D:AI驅動,秒速將2D圖像轉化為專業級3D模型
Meta的單圖像3D重建模型,融合SAM 3分割與幾何紋理佈局預測生成3D資產
Justin331
SAM 3 是 Meta 推出的第三代可提示分割基礎模型,統一支持圖像和視頻分割任務。相比前代 SAM 2,它引入了開放詞彙概念分割能力,能夠處理大量文本提示,在 SA-CO 基準測試中達到人類表現的 75-80%。
onnx-community
SAM3是基於概念的任意分割模型,能夠根據輸入的點、框等提示信息生成精確的圖像分割掩碼。該版本是ONNX格式的SAM3跟蹤器模型,通過Transformers.js庫可在瀏覽器環境中高效運行。
facebook
SAM 3 是 Meta 推出的第三代可提示分割基礎模型,能夠利用文本或視覺提示(點、框、掩碼)來檢測、分割和跟蹤圖像與視頻中的對象。與前代相比,SAM 3 引入了對開放詞彙概念所有實例進行詳盡分割的能力,支持大量開放詞彙提示,在 SA-CO 基準上達到人類表現的 75-80%。
samwell
NV-Reason-CXR-3B GGUF是NVIDIA NV-Reason-CXR-3B視覺語言模型的量化版本,專為邊緣設備部署優化。這是一個30億參數的模型,專注於胸部X光分析,已轉換為GGUF格式並進行量化處理,可在移動設備、桌面設備和嵌入式系統上高效運行。
SamuelBang
AesCoder-4B是一個專注於提升代碼美學質量的大語言模型,通過智能獎勵反饋機制優化代碼生成的美學表現,在網頁設計、遊戲開發等視覺編碼任務中表現出色。
yonigozlan
EdgeTAM是SAM 2的輕量化變體,專為設備端視頻分割和跟蹤而設計。它比SAM 2快22倍,在iPhone 15 Pro Max上可達16 FPS,支持即時視頻對象分割和跨幀跟蹤。
samuelsimko
這是一個基於Transformer架構的預訓練模型,具體功能和特性需要根據實際模型信息補充。模型支持多種下游任務,具備良好的泛化能力。
這是一個發佈在Hugging Face模型中心的Transformer模型,具體信息待補充。模型卡片為自動生成,提供了模型的基本框架但缺少詳細內容。
samunder12
基於Llama 3.1 8B Instruct微調的GGUF量化模型,具有強勢、果斷且具有挑釁性的AI人設,專為角色扮演和創意寫作場景優化,支持在CPU或GPU上進行本地推理。
John6666
Noobai-XL-1.0是基於Stable Diffusion XL技術的文本到圖像生成模型,專注於生成逼真、寫實風格的圖像,為圖像創作領域提供高質量的AI生成解決方案。
SamilPwC-AXNode-GenAI
PwC-Embedding-expr 是基於 multilingual-e5-large-instruct 嵌入模型訓練的韓語優化版本,通過精心設計的增強方法和微調策略提升在韓語語義文本相似度任務上的性能。
deepseek-community
DeepSeek-VL 是一個開源的視覺語言模型,能夠同時處理文本和圖像,生成上下文相關的響應。該模型採用混合編碼架構,結合LLaMA文本編碼器和SigLip/SAM視覺編碼器,支持高分辨率圖像處理,在真實世界應用中表現出色。
hathibelagal
Samastam是Sarvam-1模型的早期指導變體,基於Alpaca-cleaned數據集微調,支持多語言指令響應。
samuelchristlie
Wan2.1-VACE-1.3B的直接GGUF轉換版本,是一套開源的視頻基礎模型,兼容消費級GPU,擅長各種視頻生成任務。
Wan2.1-T2V-1.3B的直接GGUF轉換版本,適用於消費級GPU的視頻生成任務
mradermacher
這是Smilyai-labs/Sam-reason-S2.1模型的加權/矩陣量化版本,提供多種量化選項,適用於不同性能和精度需求。該模型經過優化,可在資源受限的環境中高效運行。
Sam-reason-S2.1的靜態量化版本,提供多種量化選項以適應不同硬件需求
Smilyai-labs
Sam-reason-S2.1是由SmilyAI開發的專注於推理的微調語言模型,具有反派風格和結構化輸出能力。
這是Smilyai-labs/Sam-reason-S2模型的靜態量化版本,提供多種量化類型選擇,適用於文本生成任務。模型經過優化,可在不同硬件配置下高效運行。
SmilyAI實驗室開發的第二代推理模型,具有諷刺反派風格AI人格,採用結構化推理輸出
一個用於生成Decent Sampler鼓組配置的MCP服務器,提供WAV文件分析、XML生成等功能。
該項目展示瞭如何將AWS Bedrock的對話式AI能力通過MCP服務器架構與關係型數據庫集成,實現自然語言查詢數據庫的功能。
一個通過MCP協議從AWS S3獲取PDF等數據的服務實現
該項目提供了一系列使用AWS Model Context Protocol(MCP)的示例模塊,涵蓋了多種語言和技術棧,包括TypeScript、Python、Spring AI等,展示了MCP在客戶端-服務器通信、ECS部署、RAG集成等場景下的應用。
一個全面的AWS成本分析與優化推薦MCP服務器,集成AWS核心服務如Cost Explorer、Compute Optimizer等,提供資源優化方案與成本節約建議。
基於AWS Lambda和SAM的Model Context Protocol(MCP)無服務器實現,提供系統配置和客戶端使用兩種接口。
一個通過MCP協議查詢AWS雲支出的工具,集成Claude模型提供自然語言交互界面。
一個基於MCP協議的TOS數據服務實現,提供存儲桶列表、對象查詢及文件獲取功能
MCP Server for ServiceNow是一個模塊化、可擴展的解決方案,通過Model Context Protocol(MCP)實現與ServiceNow的集成。它提供了一系列API工具,涵蓋ITSM、ITOM、SAM、HAM、增強型CMDB、PPM、員工體驗、報告分析、動態工具註冊和工作流編排等多種用例。該解決方案適用於與AI代理或其他外部系統集成,自動化流程如訪問配置、事件管理、資產生命週期管理等。
一個基於AWS Lambda和API Gateway的簡易Model Context Protocol (MCP) 服務器,使用Serverless Application Model (SAM)部署,支持本地開發和測試。
一個基於Linear API的MCP服務器,用於全面的項目管理,支持計劃、項目、問題和關係管理等功能。
一個MCP服務器的示例項目
嘗試使用Kotlin實現MCP服務器的示例項目
官方教程:使用TypeScript SDK創建MCP服務器
一個提供AI視覺分析能力的MCP服務器,支持網頁截圖、視覺分析、文件操作和報告生成等功能,適用於Claude等AI助手。
項目支持通過nodemon監控Python服務器文件變更自動重啟,並可自定義端口運行
C++實現的MCP Servers示例項目
一個用於控制Eufy RoboVac設備的MCP服務器,基於TypeScript和Vite構建,提供設備發現、連接和控制功能。
該項目展示瞭如何將官方TypeScript MCP服務器改造為支持流式HTTP協議,並通過Amazon Lambda部署的實現方案。核心功能包括流式傳輸協議支持、基於Lambda的彈性部署以及成本優化,適用於需要與現有HTTP基礎設施無縫集成的場景。
SAMtools MCP為SAM/BAM/CRAM文件提供標準化操作接口,支持格式轉換、排序、統計等核心功能。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)