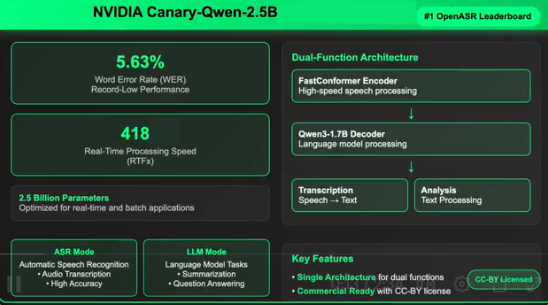
Récemment, le modèle multimodal MiMo-VL développé par Xiaomi a pris le relais de MiMo-7B et a démontré une puissance impressionnante dans plusieurs domaines. Ce modèle excelle largement sur des tâches telles que les questions-réponses et la compréhension des images, vidéos et langues par rapport aux modèles multimodaux Qwen2.5-VL-7B, qui sont du même taille. Dans la tâche de GUI Grounding, ses performances rivalisent avec celles des modèles spécialisés, préparant ainsi l'arrivée de l'ère des agents.

Le MiMo-VL-7B se distingue particulièrement dans les tâches de raisonnement multimodal, malgré sa taille de 7 milliards de paramètres seulement. Il domine nettement les modèles concurrents Alibaba Qwen-2.5-VL-72B et QVQ-72B-Preview, qui ont un paramètre dix fois plus grand, ainsi que le modèle fermé GPT-4o dans des compétitions comme OlympiadBench et MathVision, MathVerse. Lorsqu'il s'agit d'évaluer l'expérience utilisateur réelle dans le cadre des concours internes entre grands modèles, MiMo-VL-7B dépasse GPT-4o pour devenir un leader parmi les modèles open source. En termes d'applications pratiques, ce modèle se montre exceptionnel dans des déductions complexes sur des images ou des vidéos, et montre également un potentiel prometteur dans des séquences d'opérations GUI longues de plus de 10 étapes, aidant même les utilisateurs à ajouter des produits comme le Xiaomi SU7 à leur liste de souhaits.
La capacité perceptive visuelle complète de MiMo-VL-7B est due à des données pré-entraînées de haute qualité ainsi qu'à un algorithme innovant d'apprentissage par renforcement hybride en ligne (MORL). Pendant le processus de pré-entraînement en plusieurs étapes, Xiaomi a collecté, nettoyé et synthétisé des données pré-entraînées multimodales de haute qualité couvrant des paires image-texte, vidéo-texte, séquences d'opérations GUI, totalisant 2,4 billions de tokens, et ajusté progressivement les proportions de différents types de données pour renforcer la capacité de raisonnement multimodal à long terme. Le MORL combine divers signaux de retour, tels que la déduction textuelle, la perception et le raisonnement multimodal, et améliore la vitesse d'entraînement grâce à un algorithme de renforcement en ligne, améliorant globalement la performance de raisonnement et de perception du modèle ainsi que l'expérience utilisateur.
Lien connexe : https://huggingface.co/XiaomiMiMo.