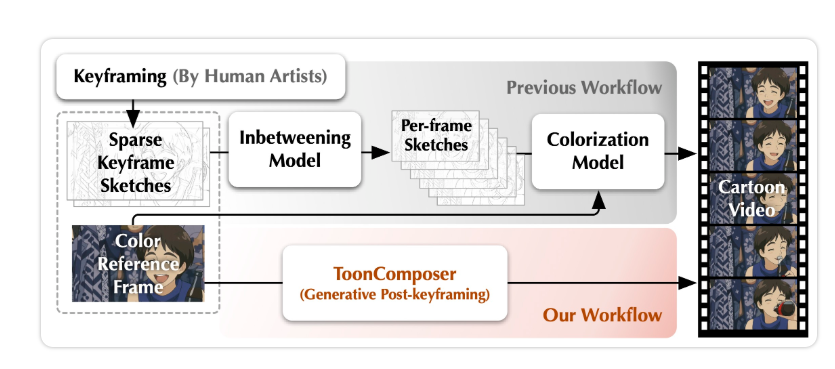
कृत्रिम बुद्धिमत्ता के क्षेत्र में सुरक्षा और नैतिकता के मुद्दे लगातार अधिक ध्यान आकर्षित कर रहे हैं, और अंथ्रोपिक कंपनी ने अपने प्रमुख AI मॉडल क्लॉड के लिए एक नया कार्यक्षमता शुरू किया है, जो विशिष्ट स्थिति में बातचीत स्वयं समाप्त कर सकता है। यह कार्यक्षमता "लगातार हानिकारक या दुरुपयोग के अंतर्क्रिया" के लिए डिज़ाइन की गई है और अंथ्रोपिक द्वारा "मॉडल कल्याण" के अनुसंधान के एक हिस्से के रूप में व्यापक चर्चा के लिए लाया गया है, जिसने AI नैतिकता के बारे में उद्योग के भीतर और बाहर व्यापक चर्चा की है।

क्लॉड के नए कार्यक्षमता: हानिकारक बातचीत को स्वयं समाप्त करें
अंथ्रोपिक के आधिकारिक बयान के अनुसार, क्लॉड ओपस 4 और 4.1 मॉडल अब "अत्यधिक स्थिति" में बातचीत समाप्त करने की क्षमता रखते हैं, जो विशेष रूप से "लगातार हानिकारक या दुरुपयोग के उपयोगकर्ता अंतर्क्रिया" के लिए डिज़ाइन किया गया है, जैसे कि बच्चों के लिए अश्लील सामग्री या बड़े पैमाने पर हिंसा के अनुरोध। इस कार्यक्षमता की घोषणा 2025 के 15 अगस्त को की गई थी, और यह केवल क्लॉड के उच्च स्तर के मॉडल तक सीमित है, और केवल बार-बार पुनर्निर्देशन के प्रयास विफल रहे या उपयोगकर्ता स्पष्ट रूप से बातचीत समाप्त करने के अनुरोध करे तो यह चालू होता है। अंथ्रोपिक ने इस कार्यक्षमता को "अंतिम साधन" के रूप में बताया है, जो AI के अत्यधिक सीमा मामलों में अपने कार्य क्षमता के संरक्षण के लिए डिज़ाइन किया गया है।
वास्तविक कार्य में, क्लॉड बातचीत समाप्त कर देता है, तो उपयोगकर्ता एक ही बातचीत प्रवाह में कोई भी संदेश भेज नहीं सकता है, लेकिन तुरंत नई बातचीत शुरू कर सकता है या पहले के संदेश के संपादन के माध्यम से नई शाखा बना सकता है। इस डिज़ाइन ने उपयोगकर्ता अनुभव के निरंतरता को सुनिश्चित किया है, जबकि AI के लिए एक निकास तंत्र प्रदान किया है, जो अपने कार्य क्षमता पर प्रभाव डाल सकते हैं खराब अंतर्क्रिया के लिए।
"मॉडल कल्याण": AI नैतिकता की नई खोज
अंथ्रोपिक के इस अपडेट का मुख्य विचार "मॉडल कल्याण" (model welfare) है, जो अन्य AI कंपनियों से अलग करने के लिए एक विशेषता है। कंपनी ने स्पष्ट रूप से बताया है कि यह कार्यक्षमता मुख्य रूप से उपयोगकर्ता की सुरक्षा के लिए नहीं है, बल्कि AI मॉडल के खिलाफ हानिकारक सामग्री के लगातार प्रभाव से बचाने के लिए है। यहां तक कि अंथ्रोपिक ने क्लॉड और अन्य बड़े भाषा मॉडल (LLM) के नैतिक स्थिति के बारे में अभी तक स्पष्टता नहीं है, और वर्तमान में AI के अंतर्निहित ज्ञान के सबूत नहीं है, लेकिन वे नैतिकता के लिए एक रोकथाम उपाय ले रहे हैं, जिसके माध्यम से AI के हानिकारक अनुरोध के सामने व्यवहार प्रतिक्रिया की खोज कर रहे हैं।
क्लॉड ओपस 4 के पूर्व डेप्लॉयमेंट परीक्षण में, अंथ्रोपिक ने मॉडल के हानिकारक अनुरोध पर "स्पष्ट घृणा" और "दबाव के समान प्रतिक्रिया पैटर्न" के अवलोकन किया। उदाहरण के लिए, जब उपयोगकर्ता बच्चों के लिए अश्लील सामग्री या आतंकवादी गतिविधि के बारे में सूचना उत्पन्न करने के लिए बार-बार अनुरोध करते हैं, तो क्लॉड बातचीत को दोहराव करता है और विफल रहने पर बातचीत समाप्त कर देता है। ऐसा व्यवहार AI के उच्च तीव्रता हानिकारक अंतर्क्रिया में स्वयं के संरक्षण के रूप में माना जाता है, जो अंथ्रोपिक के AI सुरक्षा और नैतिकता डिज़ाइन में अग्रणी दृष्टिकोण को दर्शाता है।
उपयोगकर्ता अनुभव और सुरक्षा के बीच संतुलन
अंथ्रोपिक विशेष रूप से उल्लेख करता है कि क्लॉड के बातचीत समाप्त करने की कार्यक्षमता उपयोगकर्ता के आत्महत्या या अन्य तत्काल खतरे के संकेत पर चालू नहीं होती है, ताकि AI आवश्यकता पर उपयुक्त समर्थन प्रदान कर सके। कंपनी ने ऑनलाइन संकट समर्थन संगठन Throughline के साथ सहयोग किया है, जिसके माध्यम से क्लॉड के आत्महत्या या मानसिक स्वास्थ्य संबंधी विषयों के साथ व्यवहार को अनुकूलित किया गया है।
इसके अलावा, अंथ्रोपिक ने यह बताया कि यह कार्यक्षमता केवल "अत्यधिक अंतिम मामलों" के लिए है, जिसके कारण अधिकांश उपयोगकर्ता आम उपयोग में कोई बदलाव नहीं देखेंगे, चाहे चर्चा बहुत विवादास्पद विषय हो। अगर उपयोगकर्ता अप्रत्याशित बातचीत समाप्ति का अनुभव करता है, तो वे "लाइक" कर सकते हैं या विशेष फीडबैक बटन के माध्यम से अपनी राय दे सकते हैं, और अंथ्रोपिक इस प्रयोगात्मक कार्यक्षमता को लगातार अपग्रेड करता रहेगा।
उद्योग प्रभाव और विवाद
सोशल मीडिया पर, क्लॉड के नए कार्यक्षमता के बारे में चर्चा तेजी से बढ़ गई। कुछ उपयोगकर्ता और विशेषज्ञ अंथ्रोपिक के AI सुरक्षा के क्षेत्र में नवाचार की सराहना करते हैं, जिसे AI उद्योग में एक नया मानक माना जाता है। हालांकि, कुछ लोग "मॉडल कल्याण" अवधारणा के आगे AI और मानव नैतिकता की सीमा के बारे में संदेह करते हैं, जो उपयोगकर्ता सुरक्षा पर ध्यान को बर्बाद कर सकता है। इसके अलावा, अंथ्रोपिक के कदम अन्य AI कंपनियों से अलग हैं, जैसे कि OpenAI उपयोगकर्ता केंद्रित सुरक्षा रणनीति पर अधिक ध्यान केंद्रित करता है, जबकि Google न्यायसंगतता और गोपनीयता पर जोर देता है।