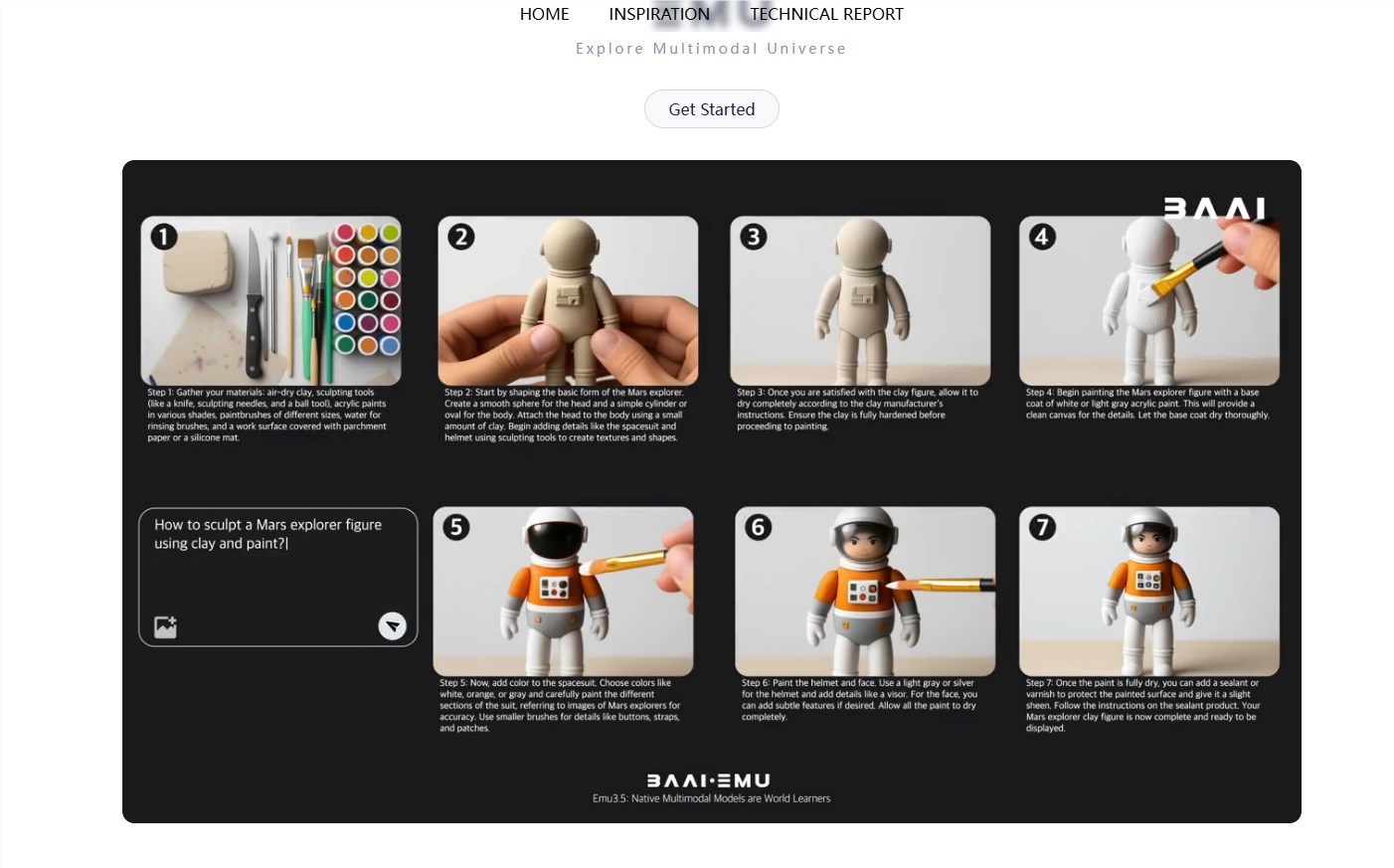
北京智源人工智能研究院发布新一代多模态大模型Emu3.5,实现“世界级统一建模”,突破传统AI在物理理解和因果推理上的短板,让AI从单纯生成图像、文本进化到真正理解物理世界。
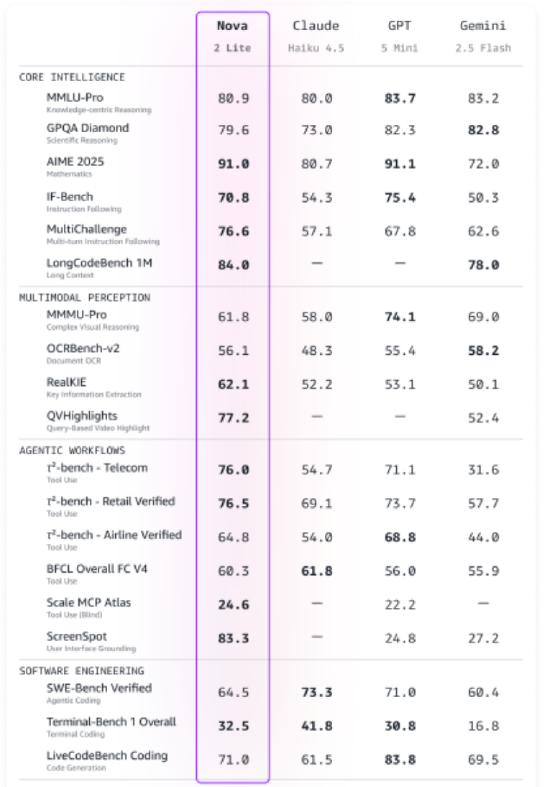
AWS在re:Invent2025大会上推出四款自研“Nova2”系列大模型,覆盖文本、图像、视频、语音多模态场景,并首次内置网页检索与代码执行能力,宣称在价格性能比上达到业界领先。其中,Nova2 Lite定位高性价比推理,在多项基准测试中表现优于Claude Haiku4.5和GPT-5Mini,成本仅为后者约50%;Nova2 Pro则面向复杂Agent任务。
亚马逊云科技在2025年re:Invent大会上推出Nova2模型系列,包括四款新模型,在推理、多模态、对话AI、代码生成和Agent任务方面具备领先性价比。其中,Nova2Lite专为日常负载设计,支持文本、图像和视频输入并生成文本输出,是一款快速经济的推理模型。
商汤科技与南洋理工大学S-Lab联合发布开源多模态模型NEO,通过架构创新实现视觉语言深层统一。该模型仅需3.9亿图像文本数据(为同类模型1/10),即可达到顶尖视觉感知性能,无需海量数据或额外视觉编码器,在效率与通用性上取得突破。
基于Flux AI模型,可实现文本生成图像和图像编辑转换
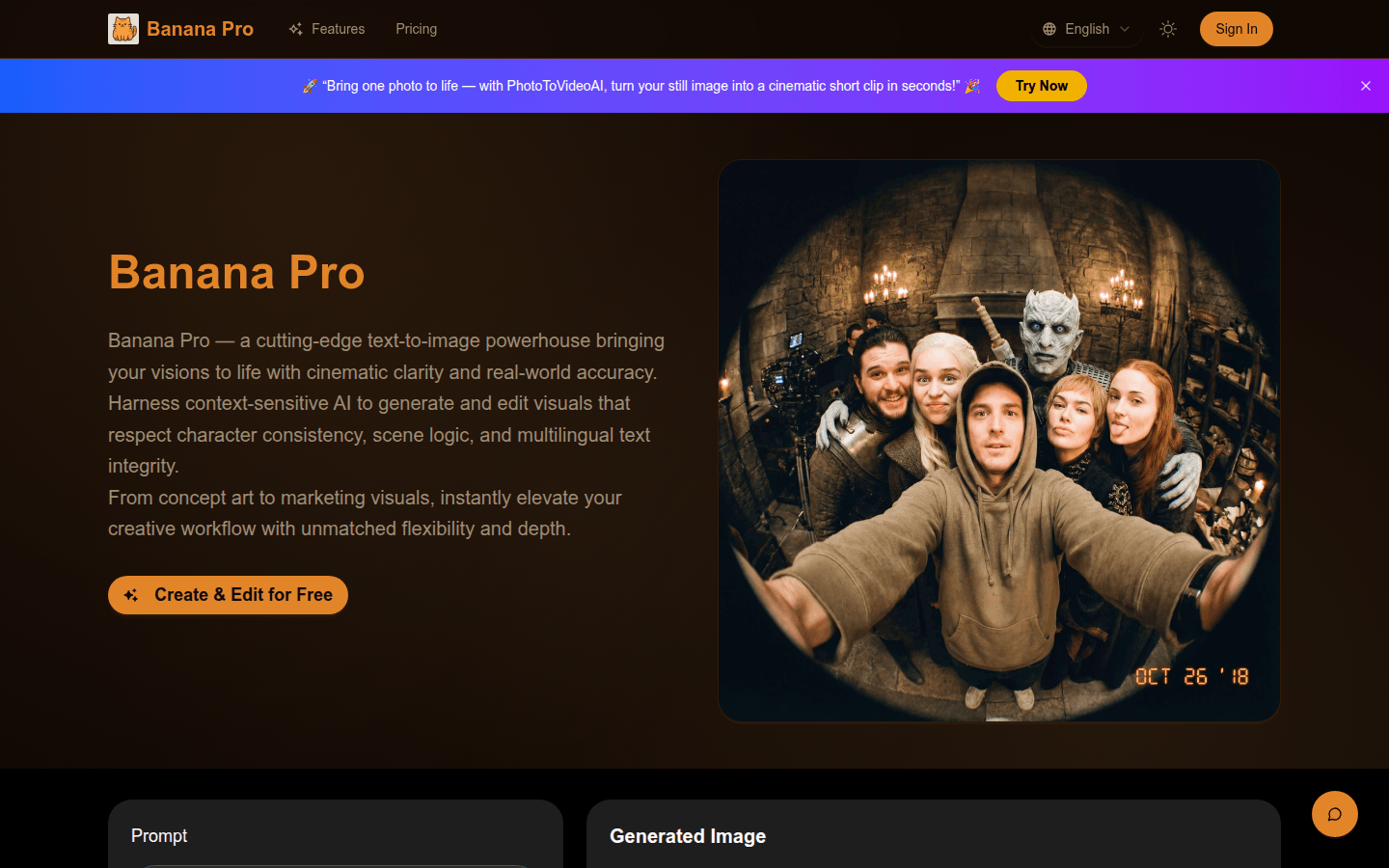
Banana Pro是下一代AI图像模型,支持文本转图像、高分辨率渲染和精确编辑
GPTunneL提供多模型AI服务,可生成文本、图像等,支持多方式支付。
先进AI技术,可将文字和图像瞬间转化为3D模型,无需3D建模经验。
Openai
$2.8
输入tokens/百万
$11.2
输出tokens/百万
1k
上下文长度
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
$6
$24
$2
$20
Baidu
128
drbaph
Z-Image(造相)是一个拥有60亿参数的高效图像生成基础模型,专门解决图像生成领域的效率和质量问题。其蒸馏版本Z-Image-Turbo仅需8次函数评估就能达到或超越领先竞品,在企业级H800 GPU上可实现亚秒级推理延迟,并能在16G VRAM的消费级设备上运行。
T5B
Z-Image-Turbo 是经过 FP8 E5M2 和 E4M3FN 格式量化的图像处理模型,基于原始 Tongyi-MAI/Z-Image-Turbo 模型优化,在保持性能的同时显著减少模型大小和推理资源需求。
city96
FLUX.2-dev是由black-forest-labs开发的图像生成和编辑模型,已转换为GGUF格式,专为图像生成任务优化,采用扩散模型架构,支持在ComfyUI框架中使用。
gguf-org
flux2-dev-gguf 是一个基于 FLUX.2-dev 的图像到图像转换模型,专门用于根据文本提示生成特定风格的图像。该模型支持在 ComfyUI 环境中运行,能够将文本描述转换为风格化的视觉内容。
silveroxides
基于 black-forest-labs/FLUX.2-dev 的优化版本图像生成模型,支持图像到图像的生成和编辑任务,采用 fp8_scaled 量化技术提升推理速度,特别适合在低显存 GPU 上使用。
ostris
这是一个基于LoRA技术的文本到图像转换模型,专门用于生成具有法国印象派画家贝尔特·莫里索艺术风格的图像。该模型在FLUX.2-dev基础模型上训练,能够将普通图像或文本描述转换为莫里索风格的画作。
Tongyi-MAI
Z-Image是一款功能强大且高效的图像生成模型,拥有60亿参数。它能有效解决图像生成领域在效率、质量和功能多样性方面的问题,为用户提供高质量的图像生成和编辑服务。
TomoroAI
TomoroAI/tomoro-colqwen3-embed-4b是一款先进的ColPali风格多模态嵌入模型,能够将文本查询、视觉文档(如图像、PDF)或短视频映射为对齐的多向量嵌入。该模型结合了Qwen3-VL-4B-Instruct和Qwen3-Embedding-4B的优势,在ViDoRe基准测试中表现出色,同时显著减少了嵌入占用空间。
diffusers
FLUX.2-dev是基于NF4量化的DiT和文本编码器的图像生成与编辑模型,提供高质量的图像生成和编辑能力,适用于图像领域的开发应用。
John1604
Qwen3 VL 4B Thinking 是一个支持图像到文本以及文本到文本转换的多模态模型,具有4B参数规模,能够满足多种图文交互需求。
pramjana
Qwen3-VL-4B-Instruct是阿里巴巴推出的40亿参数视觉语言模型,基于Qwen3架构开发,支持多模态理解和对话任务。该模型具备强大的图像理解和文本生成能力,能够处理复杂的视觉语言交互场景。
ExaltedSlayer
Gemma 3是谷歌推出的轻量级开源多模态模型,本版本为12B参数的指令调优量化感知训练模型,已转换为MLX框架的MXFP4格式,支持文本和图像输入并生成文本输出,具有128K上下文窗口和140+语言支持。
00quebec
这是一个专门为 Qwen-Image 设计的开源 LoRA 模型,专注于模拟现代 iPhone 摄影的真实感外观和感觉。模型基于5000多张真实 iPhone 风格照片训练,能够生成清晰、自然、适合社交媒体分享的图像。
black-forest-labs
FLUX.2 [dev] 是一个拥有320亿参数的校正流变压器模型,专门用于图像生成、编辑和组合任务。该模型在文本到图像生成、单参考编辑和多参考编辑方面处于领先水平,无需微调即可实现角色、对象和风格参考,支持个人、科学和商业用途。
这是一个基于Qwen Image Edit 2509的LoRA模型,专门用于将输入图像转换为带有夸张特征的素描漫画艺术作品。模型能够为人物和动物主体创作出幽默且富有艺术感的漫画形象,突出面部特征和特点。
jayn7
本项目提供了腾讯HunyuanVideo-1.5-I2V-720p模型的量化GGUF版本,专门用于图像转视频和视频生成任务。该模型支持将静态图像转换为高质量视频内容,提供了多种量化版本以优化性能。
腾讯混元视频1.5模型的量化GGUF版本,专门用于图像转视频和视频生成任务。提供480P分辨率的蒸馏模型和标准模型,支持多种量化精度,包括Q4_K_S、Q8_0和FP16等。
DejanX13
这是一个基于Google ViT-base模型微调的房屋状况分类器,能够将房屋图像分为良好、未知、破败和中等四个类别。模型在935张房屋图像数据集上训练,验证集准确率达到81.2%。
Justin331
SAM 3 是 Meta 推出的第三代可提示分割基础模型,统一支持图像和视频分割任务。相比前代 SAM 2,它引入了开放词汇概念分割能力,能够处理大量文本提示,在 SA-CO 基准测试中达到人类表现的 75-80%。
easygoing0114
Qwen-Image-Edit-2509_clear 是 Qwen-Image-Edit-2509 模型的微调版本,专门针对图像生成质量进行优化。该模型能够生成更清晰、更鲜艳的图像,具有更高的对比度、更丰富的色彩和更精细的细节表现。
MiniMax官方模型上下文协议(MCP)服务器,支持文本转语音、视频/图像生成等API交互。
mcp-hfspace是一个连接Hugging Face Spaces的MCP服务器,支持图像生成、语音处理、视觉模型等多种AI功能,简化了与Claude Desktop的集成。
AI视频生成MCP服务器,支持文本和图像输入生成动态视频,提供多种参数控制和模型选择。
MCP Server Notifier 是一个轻量级通知服务,与模型上下文协议(MCP)集成,可在AI代理完成任务时发送Webhook通知。支持多种Webhook提供商(如Discord、Slack、Teams等),提供图像支持、多项目管理、自定义消息等功能,易于与AI工具(如Cursor)集成。
该项目是一个基于Google Veo2模型的视频生成MCP服务器,支持通过文本提示或图像生成视频,并提供MCP资源访问功能。
OpenCV MCP Server是一个基于Python的计算机视觉服务,通过Model Context Protocol (MCP)提供OpenCV的图像和视频处理能力。它为AI助手和语言模型提供从基础图像处理到高级对象检测的全套计算机视觉工具,包括图像处理、边缘检测、人脸识别、视频分析和实时对象跟踪等功能。
Jina AI MCP服务器是一个提供语义搜索、图像搜索和跨模态搜索功能的模型上下文协议服务,支持与Jina AI神经搜索能力无缝集成。
OpenSCAD MCP服务器是一个通过文本或图像生成参数化3D模型的服务,支持多视角重建、AI图像生成、远程CUDA处理和工作流审批,最终输出OpenSCAD兼容的模型文件。
一个基于MCP协议的图像生成服务器,使用Replicate的flux-schnell模型,支持通过文本提示生成图像,并可配置多种参数。
OpenSCAD MCP服务器是一个通过文本或图像生成参数化3D模型的工具,支持多视角重建和远程处理。
MCPollinations是一个基于Model Context Protocol(MCP)的多模态AI服务,支持通过Pollinations API生成图像、文本和音频。它提供无需认证的轻量级服务,兼容多种AI模型,并支持图像保存和Base64编码返回。
一个基于TypeScript的MCP服务器,使用OPENAI的dall-e-3模型根据文本提示生成图像,并支持将生成的图像保存到本地指定目录。
DiffuGen是一个先进的本地图像生成工具,集成了MCP协议,支持多种AI模型(包括Flux和Stable Diffusion系列),可直接在开发环境中生成高质量图像。它提供了灵活的配置选项、多GPU支持,并可通过MCP协议与多种IDE集成,同时提供OpenAPI接口供外部调用。
一个基于Google Gemini模型的MCP服务器,提供文本生成图像和图像转换功能,支持高质量图像生成、智能文件名生成和本地存储。
Pixeltable的多模态模型上下文协议服务器集合,提供音频、视频、图像和文档的索引与查询功能
Outsource MCP是一个支持多AI模型提供商的统一接口服务,通过MCP协议让AI应用能便捷调用不同厂商的文本和图像生成能力。
一个基于Amazon Bedrock的Nova Canvas模型的MCP服务器,支持多种图像生成与编辑功能。
Moondream MCP Server是一个基于Moondream视觉模型的图像分析服务,提供图像描述生成、物体检测和视觉问答功能,可轻松集成到Claude和Cline等AI助手中。
一个基于OpenAI GPT-4o/gpt-image-1模型的图像生成与编辑工具,支持通过文本提示生成图像、编辑图像(如修复、扩展、合成等),并兼容多种MCP客户端。
Luma API MCP是一个提供图像和视频生成服务的项目,用户可以通过API密钥接入,支持多种比例、模型和分辨率选项,并能通过参考图像或视频关键帧控制生成效果。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)