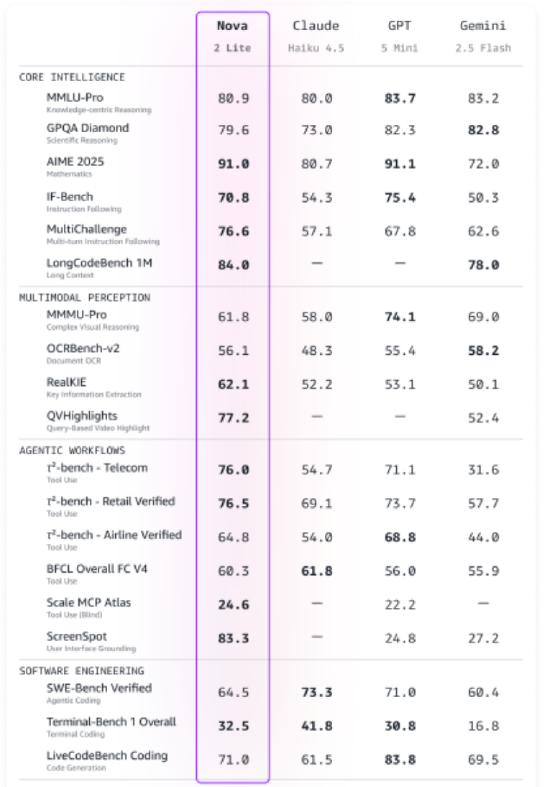
亚马逊云科技在2025年re:Invent大会上推出Nova2模型系列,包括四款新模型,在推理、多模态、对话AI、代码生成和Agent任务方面具备领先性价比。其中,Nova2Lite专为日常负载设计,支持文本、图像和视频输入并生成文本输出,是一款快速经济的推理模型。
可灵AI公司宣布其O1视频大模型已全量上线,采用统一多模态架构,支持文字、图像等多种输入方式,实现一句话生成视频。
可灵AI公司宣布,其O1视频大模型已全量开放。该模型采用多模态视觉语言统一架构,支持文字、图像、视频融合输入,并引入思维链推理,号称全球首个统一多模态视频大模型。它可一次性完成文生视频、图生视频、局部编辑及镜头延展等任务,无需分步操作。
昆仑元AI在2025世界计算大会上发布全模态融合模型BaiZe-Omni-14b-a2b,基于昇腾平台,具备文本、音频、图像和视频的理解与生成能力。采用模态解耦编码、统一跨模态融合和双分支功能设计等创新架构,推动多模态应用发展。模型流程包括输入处理、模态适配、融合、核心功能和输出解码。
Qwen2.5-VL 是一款强大的视觉语言模型,能够理解图像和视频内容并生成相应文本。
使用AI大模型一键生成高清故事短视频,支持多种语言模型和图像生成技术。
图生视频大模型,专为动漫和游戏场景设计
Openai
$2.8
输入tokens/百万
$11.2
输出tokens/百万
1k
上下文长度
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
$6
$24
Baidu
128
$2
$20
Quantamhash
开放且先进的大规模视频生成模型套件,支持文本生成视频、图像生成视频等多种任务
Isi99999
万2.1版是一个开放且先进的大规模视频生成模型,支持文本生成视频、图像生成视频等多种任务,适配消费级显卡。
THUdyh
Ola-7B是由腾讯、清华大学和南洋理工大学联合开发的多模态大语言模型,基于Qwen2.5架构,支持处理文本、图像、视频和音频输入,并生成文本输出。
wchai
AuroraCap是一个用于图像和视频字幕的多模态大语言模型,专注于高效和详细的视频字幕生成。
DAMO-NLP-SG
VideoLLaMA 2是一个多模态大语言模型,专注于视频理解和音频处理,能够处理视频和图像输入并生成自然语言响应。
LanguageBind
Video-LLaVA是一个开源的多模态模型,通过在多模态指令跟随数据上微调大语言模型进行训练,能够生成交错的图像和视频。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)