腾讯混元团队开源HY-Motion1.0模型,基于DiT架构与流匹配技术,通过文本描述即可生成高质量3D骨骼动画,兼容主流3D工具,大幅降低动画制作门槛。该模型采用全阶段训练策略,利用超3000小时动作数据优化生成效果。
阿里巴巴云发布两款AI语音模型,Qwen3-TTS-VD-Flash支持用户通过文本指令定制声音,可精确描述声音的情感、节奏等特征,实现个性化语音生成。
英伟达在NeurIPS大会上发布自动驾驶AI模型Alpamayo-R1(AR1),这是全球首个行业级开放推理视觉语言行动模型。它能同时处理文本和图像,将传感器信息转化为自然语言描述,结合推理链AI和路径规划技术,以应对复杂驾驶场景,加速无人驾驶汽车发展。
Maya Research推出Maya1文本转语音模型,30亿参数,可在单GPU实时运行。模型通过自然语言描述和文本输入,生成可控且富有表现力的语音,精准模拟人类情感与声音细节,如指定年龄、口音或角色特征。
Seedream 5.0可将文本描述瞬间转化为精美图像,免费且无限创作
NanoBananas是一款AI图像生成平台,通过简单的文本描述即可生成惊人的图像、表情和角色设计。
AI Nano Banana是一款基于AI的图像生成和编辑平台,通过简单的文本描述创建令人惊叹的视觉效果。
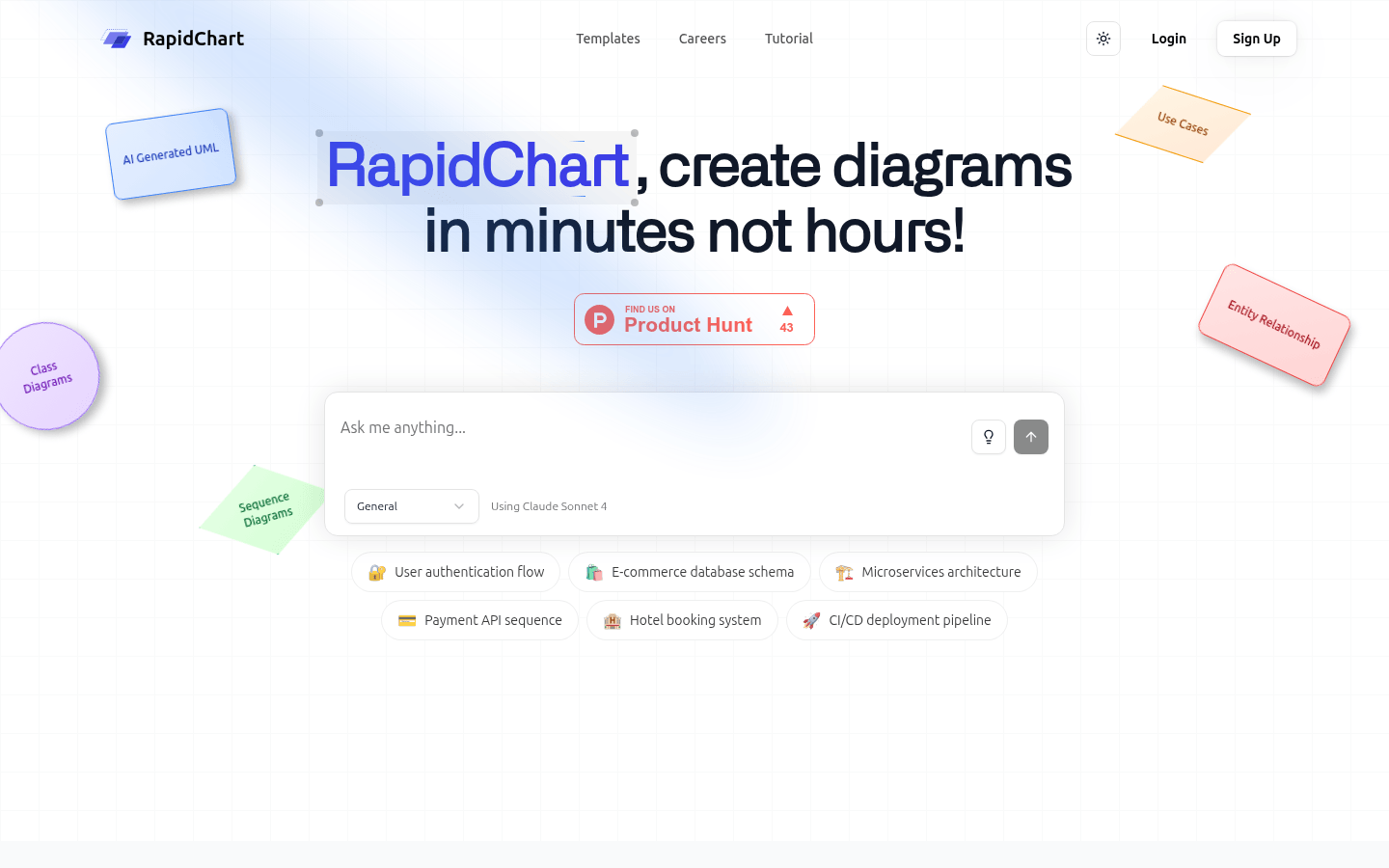
使用AI快速生成UML图表,从简单的文本描述中生成类图、ER图等。快速、直观、强大。
Openai
$2.8
输入tokens/百万
$11.2
输出tokens/百万
1k
上下文长度
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
Baidu
128
$6
$24
256
Bytedance
$1.2
$3.6
4
$2
$3.9
$15.2
64
gguf-org
flux2-dev-gguf 是一个基于 FLUX.2-dev 的图像到图像转换模型,专门用于根据文本提示生成特定风格的图像。该模型支持在 ComfyUI 环境中运行,能够将文本描述转换为风格化的视觉内容。
ostris
这是一个基于LoRA技术的文本到图像转换模型,专门用于生成具有法国印象派画家贝尔特·莫里索艺术风格的图像。该模型在FLUX.2-dev基础模型上训练,能够将普通图像或文本描述转换为莫里索风格的画作。
uriel353
Anime2Realism是一个基于Qwen/Qwen-Image基础模型的文本到图像转换模型,专门实现从动漫风格到写实风格的图像转换。该模型利用LoRA和Diffusers技术,能够根据文本描述生成相应的写实风格图像。
QuantStack
这是一个将hlwang06/HoloCine模型转换为GGUF格式的文本到视频生成模型,支持通过文本描述生成视频内容,采用Apache-2.0许可证。
GatorBarbarian
TRELLIS Text XL是一个大型3D生成模型,是TRELLIS的文本条件版本,模型大小为XL。该模型基于论文《Structured 3D Latents for Scalable and Versatile 3D Generation》提出,能够根据文本描述生成高质量的3D内容。
briaai
FIBO是首个专为长结构化描述训练的开源文本到图像模型,为可控性、可预测性和特征解耦设定了新标准。该模型拥有80亿参数,仅使用有许可的数据进行训练,支持专业工作流程需求。
lichorosario
这是一个基于Qwen-Image模型训练的LoRA(Low-Rank Adaptation)模型,专门用于文本到图像的生成任务。该项目使用AI Toolkit训练,能够将文本描述转化为高质量的图像,支持在多种图像生成工具中使用。
bghira
这是一个基于PixArt-900M-1024模型的LyCORIS适配器,专门用于文本到图像的转换任务。该模型能够根据输入的文本描述生成相应的图像,支持多种分辨率的图像生成。
rajinikarcg
这是一个基于BERT微调的软件需求二分类模型,专门用于识别和分类软件需求文档中的需求与非需求文本,准确区分功能性需求描述与其他内容。
MadhavRupala
Stable Diffusion v1-5是基于潜在扩散技术的文本到图像生成模型,能够根据文本描述生成逼真的图像。该模型在LAION-2B数据集上训练,支持英语文本输入,生成512x512分辨率的图像。
这是一个基于Qwen-Image模型使用LoRA技术进行微调的文本到图像生成模型,能够将输入的文本描述转化为对应的图像,支持生成人物形象、影视角色和特定场景等多种类型的图像。
John6666
Illustrious-xl-early-release-v0 是一款基于 Stable Diffusion XL 架构的文本到图像生成模型,专门针对动漫和2D插画风格进行优化,能够根据文本描述生成高质量的图像作品。
hunyuanvideo-community
混元图像2.1是基于diffusers库的文生图模型,能够根据文本描述生成高质量的图像,支持中英双语输入,为用户提供便捷的图像生成体验。
manycore-research
FLUX.1 Wireframe [dev] LoRA 是 FLUX.1-Layout-ControlNet 的改进版本,作为 SpatialGen 的关键组件,能够根据文本描述生成图像,同时遵循给定线框图像的结构。该模型适用于 FLUX.1 [dev] 框架,专门用于室内场景生成任务。
uwcc
poshanimals是一个基于FLUX.1-dev模型训练的文本到图像生成模型,使用AI Toolkit by Ostris训练,能够根据文本描述生成具有特定风格的图像作品。
tekoaly4
这是一个基于stabilityai/stable-diffusion-3.5-large的LyCORIS适配器,专门用于文本到图像生成,能够根据文本描述生成高质量的产品摄影图像,特别针对Borges品牌产品进行了优化。
FLUX.1-Layout-ControlNet是SpatialGen框架的关键组件,是一个基于语义图像条件化的ControlNet模型。它能够根据文本描述生成2D图像,同时严格遵循输入语义图像的布局约束,主要用于3D室内场景合成。
Immac
NetaYume Lumina Image 2.0 是一个文本到图像的扩散模型,经过GGUF格式量化处理,能够将文本描述转换为图像。该模型经过优化,在保持生成质量的同时减少了内存使用和提升了性能。
davidrd123
这是一个基于Qwen/Qwen-Image的LyCORIS适配器,专门用于文本到图像的生成任务。该模型能够根据输入的文本描述生成相应的图像,特别擅长生成具有涂鸦风格和混合媒体效果的图像内容。
duyntnet
Chroma 是一个高质量的文本到图像生成模型,专注于生成逼真的图像内容。该模型采用先进的扩散技术,能够根据文本描述生成高质量的视觉内容,特别适合本地部署环境下的图像创作需求。
基于即梦AI的图像生成服务,专为Cursor IDE设计,实现文本描述到图像的生成与保存。
一个提供图像识别功能的MCP服务器,支持Anthropic和OpenAI的视觉API,具备图像描述、多格式支持、可配置主备服务商及OCR文本提取功能。
一个基于Go语言的MCP服务器,通过OpenAI的DALL-E API实现文本描述生成图像功能,可与Claude等大型语言模型集成使用。
一个基于Google Gemini图像生成模型的MCP服务器,允许AI代理通过文本提示生成、编辑和描述图像,支持多种模型和配置选项。
Gemini Nanobanana MCP 是一个让用户通过文本描述生成AI图像的Claude插件,集成了Google Gemini 2.5 Flash图像生成功能,支持多种图像编辑和创作方式。
一个基于Inspire后端图像搜索能力的MCP服务器,提供通过文本描述搜索相似图片的功能。
MCP-Diagram是一个通过文本描述快速生成多种类型图表(如架构图、UML类图等)的服务器工具,支持与Claude等AI助手集成。
Flux Image MCP Server是一个基于Flux Schnell模型的图像生成服务,通过Replicate平台提供API接口,支持通过文本描述生成图像。
该项目实现了一个MCP服务器,通过OpenAI的gpt-image-1模型提供图像生成和编辑功能,支持文本描述生成图像、基于参考图像编辑或修复图像,并可将结果保存到本地。
一个基于Amazon Bedrock Nova Canvas模型的MCP服务器,提供高质量的AI图像生成服务,支持文本描述生成图像、负面提示优化、尺寸配置和种子控制等功能。
一个基于grep命令的MCP服务器,提供强大的文本搜索功能,支持自然语言描述和正则表达式搜索。
一个基于Freepik Flux AI的MCP服务器,用于通过文本描述生成图像,支持多种宽高比,并与Claude Desktop集成。
一个基于HTTP的图片生成服务器,通过调用Replicate的Flux Schnell模型来根据文本描述生成图像。
Nano Banana是一个专业的MCP扩展,用于通过文本描述生成、编辑和修复图像,支持多种图像处理功能,如生成图标、图案、故事和图表等。
一个基于Go语言的MCP服务器,通过OpenAI的DALL-E API实现文本描述生成图像功能,支持与Claude等大型语言模型集成。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)