三星推出全球首款集成谷歌Gemini大模型的智能冰箱,具备AI视觉识别功能,可自动识别食材、推荐食谱、生成购物清单和管理红酒收藏,重新定义厨房智能体验。
智谱团队开源四项视频生成核心技术,包括GLM-4.6V视觉理解、AutoGLM设备控制、GLM-ASR语音识别和GLM-TTS语音合成模型,展示其在多模态领域的最新进展,为视频生成技术发展奠定基础。
火山引擎发布豆包语音识别模型2.0,显著提升推理能力,支持多语言和视觉信息识别。模型基于20亿参数音频编码器,优化复杂场景,提升专有名词、人名、地名及多音字的识别准确性。
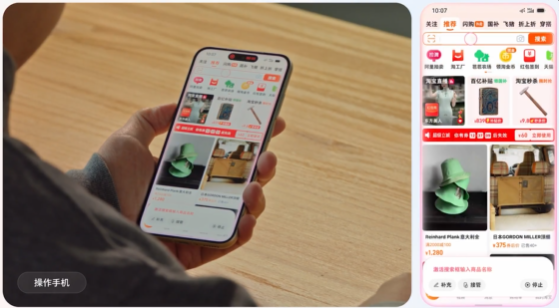
字节跳动推出“豆包手机助手”技术预览版,定位为“手机第二大脑”,具备视觉识别、记忆存储和操作执行能力。其核心亮点是端侧记忆功能,所有数据本地加密存储,并可一键关闭,提升了隐私保护。
基于UI-TARS(视觉语言模型)的GUI代理应用,可使用自然语言控制电脑。
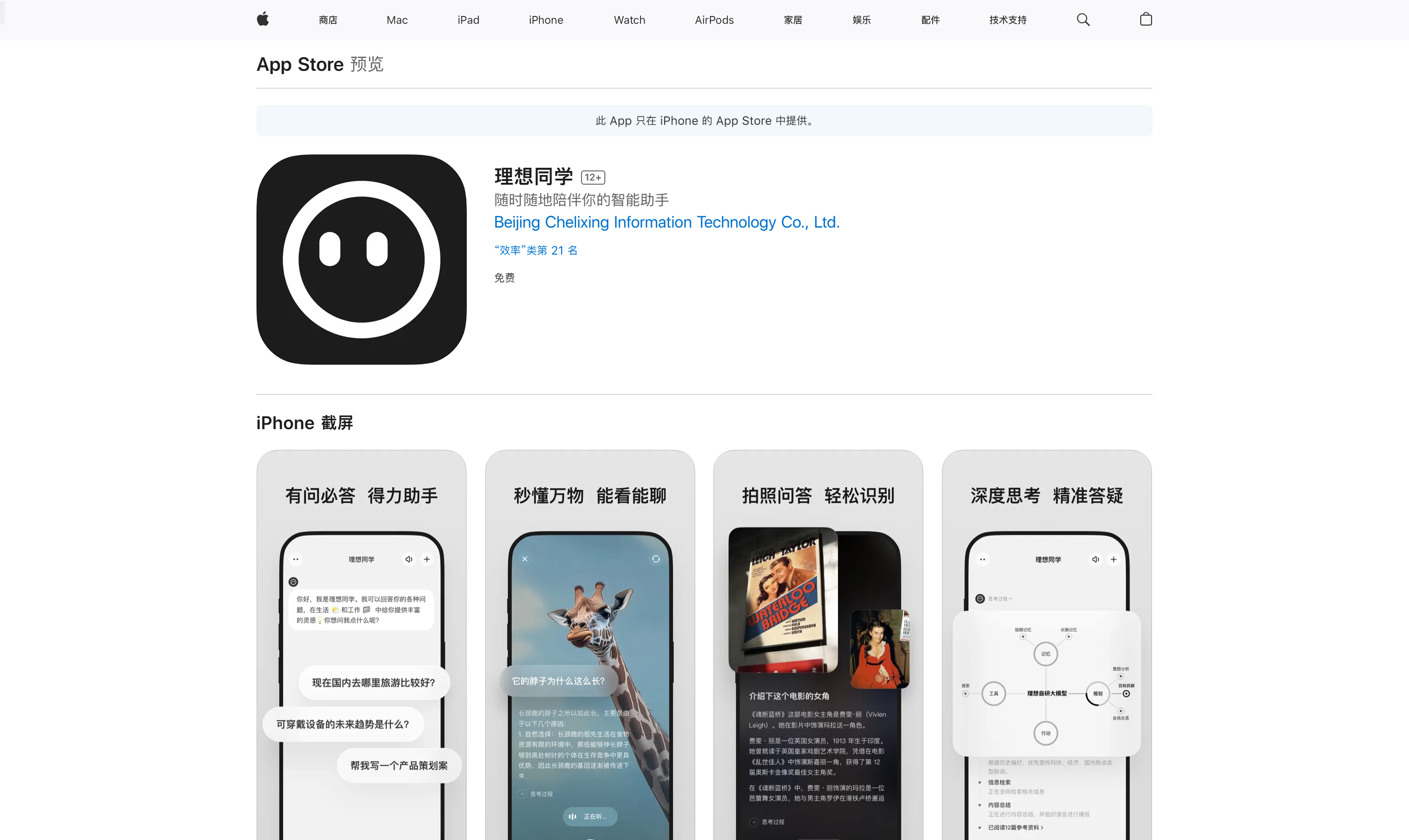
随时随地陪伴你的智能助手
视觉AI助手,提供视频信息识别与交流
视觉位置识别通过图像片段检索
Openai
$2.8
输入tokens/百万
$11.2
输出tokens/百万
1k
上下文长度
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
Anthropic
$105
$525
200
$0.7
$7
$35
$17.5
$21
Alibaba
$1
$10
256
$2
$20
-
$8
$240
52
Bytedance
$1.2
$3.6
4
$3.9
$15.2
64
$15.8
$12.7
noctrex
LightOnOCR-1B-1025的量化版本,专门用于图像转文本任务,在文档理解、视觉语言处理等领域有广泛应用。该模型支持多种欧洲语言,适用于OCR、PDF处理和表格识别等场景。
mlx-community
DeepSeek-OCR-8bit是基于DeepSeek-OCR模型转换的MLX格式版本,专门针对苹果芯片优化的视觉语言模型,支持多语言OCR识别和图像文本理解任务。
DeepSeek-OCR-6bit是基于DeepSeek-OCR模型转换的MLX格式版本,专门针对苹果芯片优化。这是一个视觉语言模型,具备强大的光学字符识别能力,能够从图像中提取和识别文本信息。
quocnguyen
该模型是基于DeepSeek-OCR转换的MLX格式视觉语言模型,专门用于光学字符识别(OCR)任务,支持多语言文本识别和图像理解
thenexthub
这是一个支持多语言处理的多模态模型,涵盖自然语言处理、代码处理、音频处理等多个领域,能够实现自动语音识别、语音摘要、语音翻译、视觉问答等多种任务。
richardyoung
olmOCR-2-7B-1025是由AllenAI开发的高质量OCR视觉语言模型,专门用于处理文档、图像中的文字识别任务。本仓库提供其GGUF量化版本,采用Q8_0量化方式,在减小模型大小的同时保持了出色的准确性。
Mungert
Nanonets-OCR2-3B GGUF模型是专为文档处理设计的强大工具,能够将各类文档智能转换为结构化的Markdown格式,具备OCR、图像转文本、PDF转Markdown以及视觉问答等多种先进识别和处理能力。
pcuenq
PaddleOCR-VL-0.9B 是一个基于 PaddlePaddle 框架开发的视觉语言模型,专门用于图像文本到文本的转换任务。该模型复刻自 PaddlePaddle 官方版本,支持从图像中提取和识别文本内容。
Mitchins
这是一个基于EfficientNet-B0架构的深度学习模型,专门用于对动漫和视觉小说图像进行艺术风格分类。模型能够准确识别6种不同的动漫艺术风格,包括暗黑、扁平、现代、萌系、绘画风和复古风格。
merve
这是一个基于DETR架构和DINOv3视觉骨干网络微调的车牌检测模型,在评估集上取得了2.7008的损失值,专门用于车牌识别任务
stanford-oval
CHURRO是一个30亿参数的开放权重视觉语言模型,专门用于历史文档转录。它能够识别跨越22个世纪和46个语言集群的手写和印刷文本,包括历史语言和已消亡语言,在显著降低成本的条件下实现了比大型商业模型更高的准确率。
tcpipuk
dots.ocr是一款强大的多语言文档解析器,将布局检测和内容识别统一在单一视觉语言模型中,基于17亿参数实现SOTA性能,支持多语言文档解析和良好的阅读顺序保持。
LZXzju
UI-R1-E-3B是基于Qwen2.5-VL-3B-Instruct微调的高效GUI定位模型,专注于视觉问答任务,特别擅长在用户界面截图中定位和识别操作元素。
NAMAA-Space
专为阿拉伯文光学字符识别(OCR)设计的视觉语言模型,能直接识别图像中的阿拉伯文字。
Freepik
专为NSFW内容分级微调的视觉Transformer模型,可识别中性/轻度/中度/重度四级内容风险
fahadh4ilyas
Llama 3.2-Vision是Meta开发的多模态大语言模型,具备图像推理和文本生成能力,支持视觉识别、图像描述和问答等任务。
actavkid
这是一个经过微调的视觉变换器模型,专门用于对12种皮肤病变进行分类。模型基于预训练的ViT架构,在约70k张皮肤病变图像上进行了微调,能够准确识别包括黑色素瘤、基底细胞癌等多种皮肤疾病。
wwwyyy
TimeZero是一种基于推理引导的大型视觉语言模型(LVLM),专为时间视频定位(TVG)任务设计,通过强化学习方法实现视频中与自然语言查询相对应的时序片段识别。
zackriya
一个专注于从图像中提取结构化数据(JSON)的视觉语言模型,特别擅长识别图表中的节点、边及其子属性,将视觉信息表示为知识图谱。
mestrevh
这是一个在豆类数据集上微调的视觉变换器(ViT)模型,用于识别豆类叶片的病害情况。
OpenCV MCP Server是一个基于Python的计算机视觉服务,通过Model Context Protocol (MCP)提供OpenCV的图像和视频处理能力。它为AI助手和语言模型提供从基础图像处理到高级对象检测的全套计算机视觉工具,包括图像处理、边缘检测、人脸识别、视频分析和实时对象跟踪等功能。
OpenRouter图像MCP服务器为AI代理提供强大的图像分析能力,支持多种视觉模型,可分析照片、网页截图、移动应用界面等视觉内容
TEN Agent是一个多功能AI代理框架,集成了实时视觉、语音识别和屏幕共享检测能力,支持快速扩展开发。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)