2026年5月28日,全球AI评测平台Artificial Analysis发布语音排行榜,阿里巴巴的Fun-Realtime-TTS-Preview语音大模型以1190分获全球第五、国产第一。该模型在ASR等三大核心语音赛道均居国内榜首,展现全面领先实力。
小米发布MiMo-V2.5全链路语音模型系列,包括三款TTS模型和一款开源ASR模型,覆盖语音输入与输出。TTS模型能精准调度情绪、语气和角色身份,让声音可编程、可创作、可复刻,提升人机交互自然度,开启语音智能新纪元。
小米发布MiMo-V2.5系列大模型,包含MiMo-V2.5、V2.5-Pro及配套TTS与ASR模型,标志着模型从“能用”到“好用”的升级。其中旗舰型号MiMo-V2.5-Pro在通用智能体能力和软件工程方面已能与Claude Opus4.6、GPT-5.4等顶尖模型竞争,核心优势在于高指令遵循度和自我修正能力。
微软开源VibeVoice语音AI模型,支持ASR和TTS,具备长音频处理、多说话人对话生成及实时低延迟特性,已在GitHub获27K星。采用MIT协议,支持本地部署,无需云端费用,旨在推动语音合成领域创新。
Seed Audio AI 含 TTS、ASR 等,通过 API 为创作者和开发者生成音频
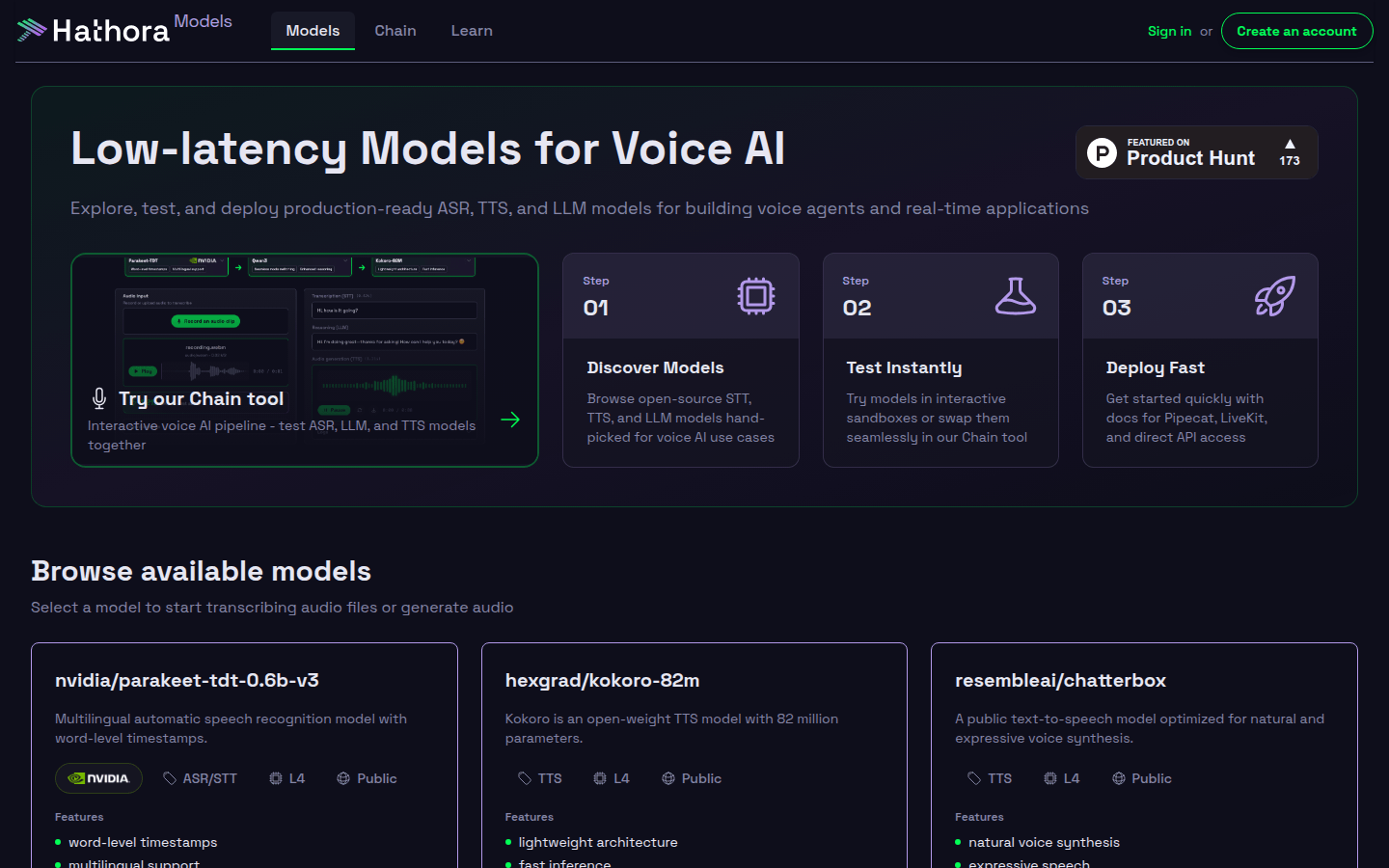
提供语音AI的ASR、TTS和LLM模型,可测试部署用于实时应用。
Nexa SDK可在数分钟内将AI模型部署到任何设备上,快速、私密且适用于多场景。
PengChengStarling 是一个基于 icefall 项目的多语言自动语音识别(ASR)模型开发工具包。
Anthropic
$7
输入tokens/百万
$35
输出tokens/百万
200
上下文长度
Alibaba
-
Chatglm
128
ai-sage
GigaAM-v3是基于Conformer架构的俄语自动语音识别基础模型,拥有2.2-2.4亿参数。它是GigaAM系列的第三代模型,在70万小时俄语语音数据上使用HuBERT-CTC目标进行预训练,在广泛的俄语ASR领域提供最先进的性能。
abr-ai
这是一个由Applied Brain Research(ABR)开发的基于状态空间模型(SSM)的英文自动语音识别模型,拥有约1900万参数,能够高效准确地将英文语音转录为文本。该模型在多个基准数据集上表现出色,平均单词错误率仅为10.61%,支持实时语音识别并可在低成本硬件上运行。
Vikhrmodels
Borealis 是首款面向俄语的自动语音识别(ASR)音频大语言模型,经过约7000小时俄语音频数据训练。该模型支持识别音频中的标点符号,架构受Voxtral启发但有所改进,在多个俄语ASR基准测试中表现优异。
openchs
基于OpenAI Whisper Large v2在Common Voice 17.0斯瓦希里语数据集上微调的语音识别模型,专为坦桑尼亚儿童求助热线的斯瓦希里语语音识别任务设计,相比基础模型在斯瓦希里语识别准确率上有显著提升。
MediaTek-Research
Breeze ASR 25 是一款基于 Whisper-large-v2 微调的先进自动语音识别模型,特别优化了台湾普通话和普通话-英语代码切换场景的识别能力。
unsloth
Whisper是一个预训练的自动语音识别(ASR)和语音翻译模型,通过68万小时标注数据训练,具有强大的泛化能力。
Whisper是OpenAI开发的最先进的自动语音识别(ASR)和语音翻译模型,在超过500万小时的标记数据上训练,具有强大的零样本泛化能力。Turbo版本是原版的修剪微调版本,解码层从32层减少到4层,速度大幅提升但质量略有下降。
Whisper是OpenAI开发的最先进的自动语音识别(ASR)和语音翻译模型,支持多种语言
istupakov
NVIDIA Parakeet TDT 0.6B V2 是一个基于自动语音识别(ASR)任务的模型,适用于英语语音转文本任务。
mlx-community
该模型是基于FastConformer架构的日语自动语音识别(ASR)模型,由NVIDIA开发并转换为MLX格式。
ibm-granite
Granite-speech-3.3-2b是IBM开发的紧凑高效语音语言模型,专为自动语音识别(ASR)和自动语音翻译(AST)设计,采用双通设计提高模块化和安全性。
GigaAM v2 是一个自动语音识别(ASR)模型,支持俄语语音转文本任务,提供CTC和RNN-T两种架构。
benax-rw
KinyaWhisper是基于OpenAI Whisper模型微调的卢旺达语自动语音识别(ASR)系统,专为低资源土著语言设计。
专为自动语音识别(ASR)和自动语音翻译(AST)设计的紧凑高效语音语言模型,采用双阶段设计处理音频和文本
Purfview
Distil-Whisper是Whisper模型的蒸馏版本,针对自动语音识别(ASR)任务进行了优化,提供更快的推理速度。
sbapan41
Quantum_STT 是一种先进的自动语音识别(ASR)和语音翻译模型,基于大规模弱监督训练,支持多种语言和任务。
asr-africa
基于facebook/w2v-bert-2.0微调的豪萨语语音识别模型,在500小时豪萨语数据上训练,词错误率7.47%
waveletdeboshir
GigaAM-v2-RNNT 是一个俄语自动语音识别(ASR)模型,基于RNNT架构,适用于语音转文本任务。
Granite-speech-3.2-8b 是一款紧凑高效的语音语言模型,专为自动语音识别(ASR)和自动语音翻译(AST)设计。
pluttodk
目前最快的丹麦语ASR模型,是hviske-v2的蒸馏版本,速度提升约4倍且保持准确率不变。
ASR MCP服务器是一个基于whisper引擎的自动语音识别服务,通过MCP工具提供语音合成功能,便于应用集成。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)