微软为Microsoft 365 Copilot推出Critique功能,首次整合GPT与Claude协同工作。GPT负责生成研究初稿,Claude则扮演审稿人角色,严格核查内容准确性与完整性,实现多模型协作处理复杂学术任务。
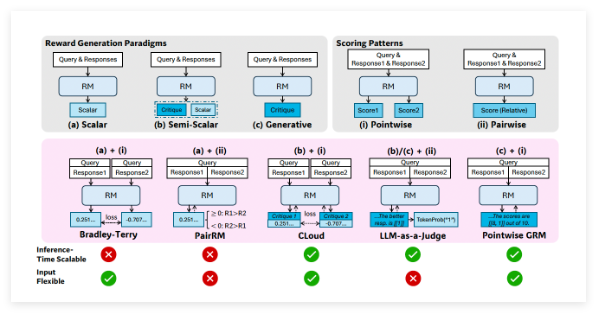
备受瞩目的中国人工智能研究实验室DeepSeek AI,继其强大的开源语言模型DeepSeek-R1之后,再次在大型语言模型(LLM)领域取得重大突破。近日,DeepSeek AI正式推出一项名为自主演原则的批判调优(Self-Principled Critique Tuning,简称SPCT)的创新技术,旨在构建更通用、更具扩展性的AI奖励模型(Reward Models,简称RMs)。这项技术有望显著提升AI在开放式任务和复杂环境中的理解和应对能力,为更智能的AI应用铺平道路。背景:奖励模型——强化学习的“指路明灯”在开发先进的LLM的过程中,强化学习(Reinfo
["智谱 AI 发布了针对中文大模型的评测基准 AlignBench","AlignBench 能够在多维度上细致评测模型和人类意图的对齐水平","数据集分为 8 个大类,包括知识问答、写作生成、角色扮演等多种类型的问题","开发者可以利用 AlignBench 进行评测,并使用评价能力较强的打分模型进行评分","通过登录 AlignBench 网站,提交结果可以使用 CritiqueLLM 作为评分模型进行评测"]
["智谱 AI 发布高质量、低成本的评分模型 CritiqueLLM","传统评价指标如 BLEU 和 ROUGE 缺乏对整体语义的把握","CritiqueLLM 提出可解释、可扩展的文本质量评价模型","在 8 类常见任务中,CritiqueLLM 优于其他模型","CritiqueLLM 通过用户询问增广、含参考文本评价数据收集、无参考文本评价数据改写和训练模型的方法生成评分"]
BBQGOD
DeepSeek-GRM-16B 是一个基于 Self-Principled Critique Tuning (SPCT) 的生成式奖励模型,能为查询-响应生成透明的'原则→批判→分数'评估流程,可用于大语言模型的强化学习、评估和数据收集等任务。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)