北京智源人工智能研究院(BAAI)最近推出了全球首个中文大模型辩论平台FlagEval Debate。这一新平台旨在通过模型辩论这一竞争机制,为大语言模型的能力评估提供新的度量方式。它是智源模型对战评测服务FlagEval大模型角斗场的扩展,目标是甄别大语言模型之间的能力差异。
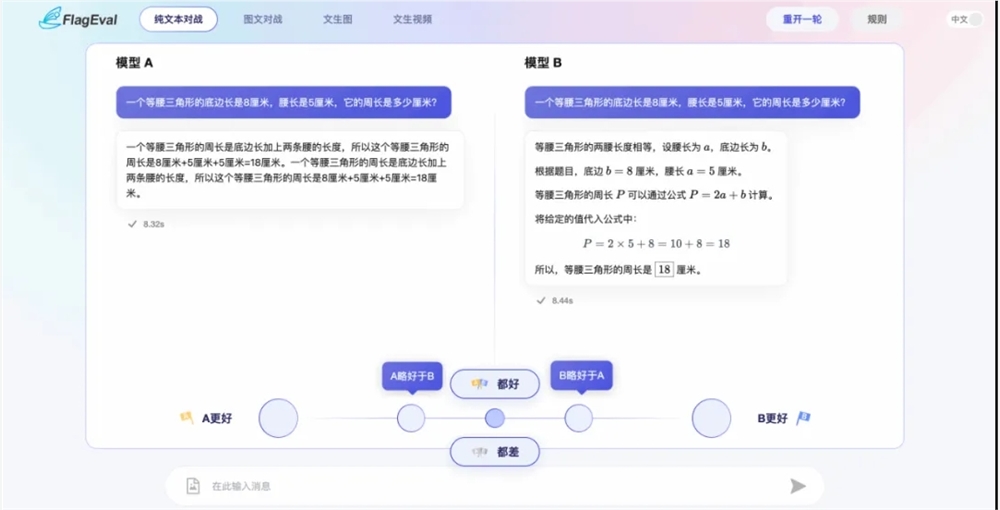
2024年9月4日,北京智源人工智能研究院(BAAI)宣布推出全球首个包含文生视频的模型对战评测服务——FlagEval大模型角斗场。这一服务面向用户开放,覆盖了国内外约40款大模型,并支持语言问答、多模态图文理解、文生图、文生视频等四大任务的自定义在线或离线评测。F
["参数量不是评判大模型的唯一标准,评测集的不同会导致排名差异巨大","主观题比例上升也会影响排名,评测公正性容易受质疑","OpenCompass和FlagEval等第三方评测机构开始受关注","学界认为还应考量模型鲁棒性、安全性等多维度","真正全面有效的评测方式仍在探索中"]
模型评测平台
一个由FlagEval提供的辩论空间
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)