在 AI 时代,大型语言模型(LLM)就像武林秘籍,其训练过程耗费巨大算力、数据,就像闭关修炼多年的武林高手。而开源模型的发布,就像高手将秘籍公之于众,但会附带一些许可证(如 Apache2.0和 LLaMA2社区许可证)来保护其知识产权(IP)。然而,江湖险恶,总有“套壳”事件发生。一些开发者声称自己训练了新的 LLM,实际上却是在其他基础模型(如 Llama-2和 MiniCPM-V)上进行包装或微调。 这就好像偷学了别人的武功,却对外宣称是自己原创的。为了防止这种情况发生,模型所有者和第三方迫
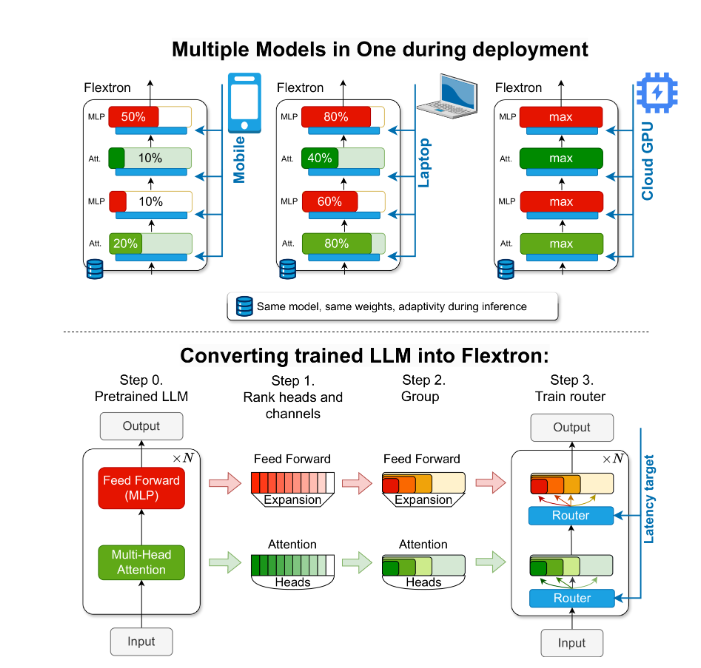
在AI领域,大型语言模型(LLMs)展现出了极高的语言理解和生成能力,如GPT-3和Llama-2等。然而,这些模型的庞大参数量对训练和部署提出了高资源需求的挑战,传统的解决办法是训练多版本模型以适应不同计算环境,但这种做法效率低下。为此,NVIDIA和德克萨斯大学奥斯汀分校提出Flextron框架,一种支持无需额外微调的灵活模型架构和优化方法。Flextron能根据特定的延迟和准确性需求,在推理过程中动态调整模型部署,显著减少对多个模型变体的依赖。通过样本高效训练方法和先进的路由算法,Flextron将预训练的LLMs转化为能够适应各种部署场景的弹性模型,节省计算资源和时间。对比其他最先进的弹性网络,Flextron在效率和准确性上都有出色表现,并通过弹性多头注意力层进一步优化资源利用,特别适合资源有限的计算环境。
"美国国防部最近启动了一项赏金计划,旨在寻找人工智能模型中的法律偏见。该计划要求参与者从Meta的开源LLama-270B模型中提取明显的偏见例证。通过这一举措,五角大楼希望改"
["Colossal-AI 团队以低成本构建了性能卓越的中文 LLaMA-2 模型","中文版 LLaMA-2 在多个评测榜单中表现优异","Colossal-AI 开源了完整的训练流程、代码及权重","Colossal-AI 提供了评估体系框架 ColossalEval","Colossal-AI 的方案可用于构建任意垂类领域的大模型"]
Baidu
-
输入tokens/百万
输出tokens/百万
32
上下文长度
Alibaba
$0.5
Google
$0.7
$1.4
131
Tencent
$4
$12
28
Deepseek
$1
8
01-ai
4
200
Baichuan
Bytedance
$5
$9
256
MerantixMomentum
ACIP项目提供的Llama-2-13b可压缩版本,支持动态调整压缩率
Mungert
Llama 2是由Meta开发的7B参数规模的大语言模型,提供多种量化版本以适应不同硬件需求。
SURESHBEEKHANI
基于Llama-2-7b微调的医学对话模型,用于回答医学相关问题并提供详细知识。
matrixportalx
这是一个基于Meta的Llama-2-7b-chat-hf模型转换而来的GGUF格式版本,采用Q4_K_M量化技术,适用于llama.cpp推理框架,支持高效的文本生成和对话任务。
matrixportal
Meta发布的Llama 2系列7B参数聊天模型GGUF量化版本,适用于本地部署和推理
diffusionfamily
基于Llama-2-7b微调的扩散语言模型
miulab
LLaMA-2 Reward Model是基于LLaMA-2-7B架构训练的奖励模型,通过模型融合技术为奖励模型赋予领域知识。该模型在argilla/ultrafeedback-binarized-preferences-cleaned数据集上训练,专门用于文本分类任务,具有重要的研究和应用价值。
tanusrich
基于LLaMA-2-7b微调的心理健康辅助对话模型,提供共情支持和非评判性心理帮助
inceptionai
Jais Adapted 13B是基于Llama-2架构的双语(阿拉伯语-英语)大语言模型,通过自适应预训练增强阿拉伯语能力
Jais系列是基于Llama-2架构的双语大语言模型,专为阿拉伯语优化同时具备强大英语能力。本模型为700亿参数规模的阿拉伯语自适应版本,支持4,096上下文长度。
Jais系列是专精阿拉伯语处理的双语大语言模型,基于Llama-2架构进行阿拉伯语适配预训练
Jais系列是专为阿拉伯语优化的英阿双语大语言模型,基于Llama-2架构进行自适应预训练,具备强大的双语处理能力。
varma007ut
基于Llama-2-7b微调的印度法律专用对话模型,专注于提供印度法律相关问题的回答。
HiTZ
Latxa是基于LLaMA-2架构的巴斯克语大语言模型,专为低资源语言设计,在42亿token的巴斯克语料库上训练
NikolayKozloff
这是一个基于Llama-2-7b架构的乌克兰语和英语语言模型,已转换为GGUF格式,适用于llama.cpp框架。
sudipto-ducs
InLegalLLaMA是基于Llama-2-7B在印度法律和科学数据集上微调的大语言模型,专门针对法律文本生成任务进行优化,适用于印度法律领域的应用场景。
tartuNLP
Llama-2-7b-乌克兰语版是一个支持乌克兰语和英语的双语预训练模型,基于Llama-2-7b继续预训练,使用了来自CulturaX的50亿token数据。
RedHatAI
这是一个基于Meta的Llama 2 7B模型进行微调的算术推理模型,专门针对GSM8K数学问题数据集进行了优化,在数学推理任务上表现出色。
Bohanlu
基於台語-Llama-2系列模型構建,專注於台灣閩南語與繁體中文、英語之間的翻譯任務。
ChrisPuzzo
基于Llama2-7B-Chat模型微调的隐私政策问答与摘要工具
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)