三星电子正加速布局AI PC芯片,其自研加速处理器代号“GAIA”计划2027年量产。该芯片由系统LSI事业部主导,基于4nm工艺,核心围绕NPU设计,专注生成式AI任务加速。原型已送测联想、惠普等厂商,进入性能验证阶段。
三星推出代号“GAIA”的生成式AI加速芯片,以专用NPU切入AI PC市场。该芯片采用4纳米工艺和“存储中心型”架构设计,已向联想、惠普等厂商提供原型验证,目标2027年量产,是三星移动NPU技术向PC场景的延伸。
谷歌在2026年I/O大会上发布全新Coral Board开发板,一款专为端侧AI设计的紧凑型单板计算机。核心采用基于RISC-V架构的开源Coral NPU,搭载Synaptics Astra SL2619芯片,配备2GHz双核处理器与2GB内存,具备1TOPS本地算力,主要面向耳机、AR眼镜及智能手表等小型设备,旨在解决AI加速器碎片化问题。
谷歌等科技巨头正竞逐本地运行大模型的新赛道。谷歌宣布将于2026年夏季推出珊瑚AI开发板,内置高性能NPU芯片,提供高达1TOPS算力,使AI硬件开发者无需依赖云端和网络,即可在本地无网环境下流畅运行大模型。
新一代骁龙X系列,搭载NPU,为创作者带来革新工具。
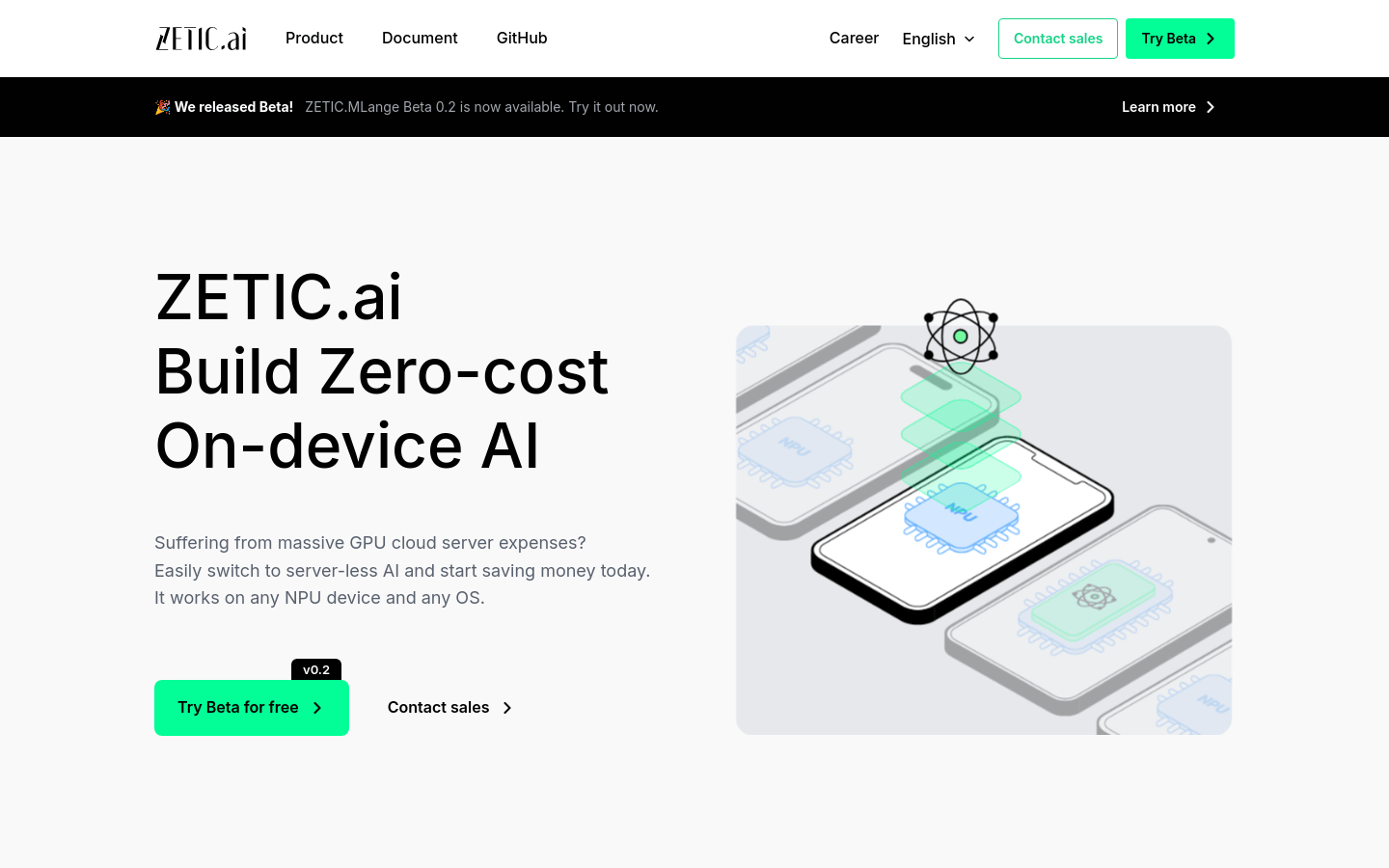
构建零成本的设备端AI。
英特尔神经处理单元加速库
Openai
$0.63
输入tokens/百万
$3.15
输出tokens/百万
131
上下文长度
Alibaba
-
Google
$0.14
$0.28
$0.35
$0.7
$1.4
Deepseek
$1
8
$2
128
NexaAI
Qwen3-VL-4B-Instruct是阿里云Qwen团队推出的40亿参数指令调优多模态大语言模型,专为高通NPU优化,融合强大的视觉语言理解能力与对话微调功能,适用于聊天推理、文档分析和视觉对话等实际应用场景。
amd
Llama-3.1-8B-onnx-ryzenai-npu是由AMD基于Meta的Llama-3.1-8B模型开发的优化版本,专门针对AMD Ryzen AI NPU进行优化部署。该模型通过Quark量化、OGA模型构建器和NPU专用后处理技术,在保持高质量文本生成能力的同时,显著提升了在AMD硬件上的推理效率。
OmniNeural是全球首个专门为神经处理单元(NPU)设计的全多模态模型,能够原生理解文本、图像和音频,可在PC、移动设备、汽车、物联网和机器人等多种设备上运行。
FastFlowLM
这是基于Meta AI的LLaMA 3.1基础模型的衍生模型,专门针对AMD Ryzen™ AI NPU上的FastFlowLM进行了优化,仅适用于XDNA2架构。模型保留了Meta发布的核心架构和权重,可能针对特定应用进行了微调、量化或适配。
这是Meta AI发布的LLaMA 3.2 1B Instruct模型的优化变体,专门针对AMD Ryzen™ AI NPU(XDNA2架构)上的FastFlowLM进行优化。模型保留了原始架构和权重,通过量化、底层调优等技术提升在NPU上的运行效率。
stabilityai
AMD Ryzen™ AI优化版SDXL-Turbo,全球首个采用Block FP16格式的文本生成图像模型,专为AMD XDNA™ 2 NPU设计
c01zaut
MiniCPM-V 2.6是支持单图、多图和视频理解的GPT-4V级别多模态大语言模型,专为RK3588 NPU优化
Phi-3.5-mini-instruct是微软开发的高效小型语言模型,采用先进的量化技术优化,专为NPU部署设计。该模型在文本生成任务中表现出色,支持自然语言处理和代码相关场景。
本项目基于Meta-Llama-3-8B模型,采用Quark量化技术,结合OGA模型构建器,并进行后处理以适配NPU部署,可用于文本生成任务。该模型专为AMD NPU硬件优化,支持高效的推理部署。
Pelochus
本仓库收集了通过瑞芯微rkllm工具包适配的各类大语言模型,专为RK3588 NPU转换的模型。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)