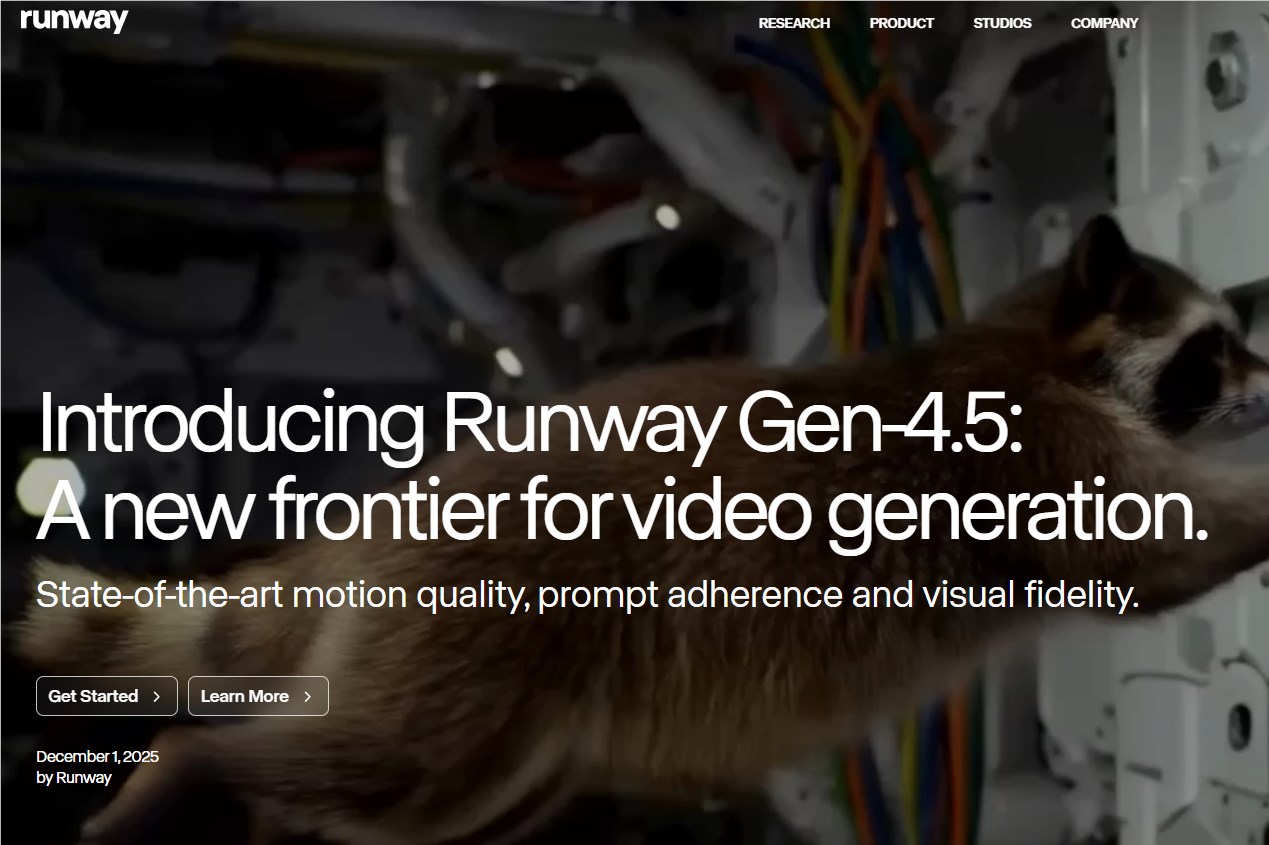
Runway发布最新视频生成模型Gen-4.5,专为创作者、影视制作人和企业用户设计,即将向所有订阅层级开放。该模型在文本转视频基准测试中以1247分领先,超越谷歌Veo3等竞品,成为当前最强文生视频模型。其卓越性能得益于先进的NVIDIA Hopper与Blackwell GPU平台支持。
英伟达在NeurIPS大会上推出新AI基础设施和模型,推动物理AI发展,助力机器人和自动驾驶车辆感知真实世界。重点发布Alpamayo-R1,首个专为自动驾驶设计的开放推理视觉语言模型,能处理文本与图像,提升车辆环境感知能力。
Runway发布新一代视频生成模型Gen-4.5,显著提升视觉准确性与创意控制能力。用户通过简短文本提示即可生成高清动态视频,支持复杂场景与生动角色。该模型基于Nvidia GPU进行训练与推理,优化生成精度与风格表现。
NVIDIA推出ToolOrchestra方法,通过训练小型语言模型Orchestrator-8B作为“大脑”,提升AI系统选择合适模型和工具的能力,避免依赖单一大型模型。该方法旨在解决传统AI代理使用单一模型时可能出现的决策偏差问题,实现更高效的任务处理。
NVIDIA GeForce RTX 5070 Ti显卡,采用Blackwell架构,支持DLSS 4技术,为游戏和创作带来强大性能。
将PDF转换为音频内容,打造个性化的AI有声读物。
NVIDIA® GeForce RTX™ 5090是迄今为止最强大的GeForce GPU,为游戏玩家和创作者带来变革性能力。
NVIDIA-Ingest是用于文档内容和元数据提取的微服务。
nvidia
-
输入tokens/百万
输出tokens/百万
128k
上下文长度
kayte0342
ChronoEdit-14B是NVIDIA开发的一款具备时间推理能力的图像编辑和世界模拟模型,拥有140亿参数。它通过两阶段推理过程实现物理感知的图像编辑和基于动作条件的世界模拟,从预训练视频生成模型中提炼先验知识。
NVIDIA Nemotron Parse v1.1 TC 是一款先进的文档语义理解模型,能够从图像中提取具有空间定位的文本和表格元素,生成结构化注释,包括格式化文本、边界框和语义类别。相比前一版本,速度提升20%,并保留无序元素的页面顺序。
NVIDIA Nemotron Parse v1.1 是一款先进的文档解析模型,专门用于理解文档语义并提取具有空间定位的文本和表格元素。它能够将非结构化文档转换为机器可读的结构化表示,克服了传统OCR在处理复杂文档布局时的局限性。
samwell
NV-Reason-CXR-3B GGUF是NVIDIA NV-Reason-CXR-3B视觉语言模型的量化版本,专为边缘设备部署优化。这是一个30亿参数的模型,专注于胸部X光分析,已转换为GGUF格式并进行量化处理,可在移动设备、桌面设备和嵌入式系统上高效运行。
DevQuasar
这是NVIDIA基于Qwen3架构开发的32B参数奖励模型,专门用于强化学习中的奖励评分和原则对齐,帮助训练更安全、更符合人类价值观的AI系统。
bartowski
这是英伟达Qwen3-Nemotron-32B-RLBFF大语言模型的GGUF量化版本,使用llama.cpp工具进行多种精度量化,提供从BF16到IQ2_XXS共20多种量化选项,适用于不同硬件配置和性能需求。
QuantStack
这是NVIDIA ChronoEdit-14B-Diffusers模型的GGUF量化版本,专门用于图像转视频任务。该模型保留了原始模型的所有功能,同时通过GGUF格式优化了部署和运行效率。
Qwen
Qwen3-VL-2B-Thinking是Qwen系列中最强大的视觉语言模型之一,采用GGUF格式权重,支持在CPU、NVIDIA GPU、Apple Silicon等设备上进行高效推理。该模型具备出色的多模态理解和推理能力,特别增强了视觉感知、空间理解和智能体交互功能。
TheStageAI
TheWhisper-Large-V3是OpenAI Whisper Large V3模型的高性能微调版本,由TheStage AI针对多平台(NVIDIA GPU和Apple Silicon)的实时、低延迟和低功耗语音转文本推理进行了优化。
NVIDIA-Nemotron-Nano-VL-12B-V2-FP4-QAD 是 NVIDIA 推出的自回归视觉语言模型,基于优化的 Transformer 架构,能够同时处理图像和文本输入。该模型采用 FP4 量化技术,在保持性能的同时显著减少模型大小和推理成本,适用于多种多模态应用场景。
NVIDIA-Nemotron-Nano-VL-12B-V2-FP8 是 NVIDIA 推出的量化视觉语言模型,采用优化的 Transformer 架构,在商业图像上进行了三阶段训练。该模型支持单图像推理,具备多语言和多模态处理能力,适用于图像总结、文本图像分析等多种场景。
BR-RM是一种创新的两轮推理奖励模型,通过自适应分支和基于分支的反思机制,解决了传统奖励模型中的'判断扩散'问题,在多个奖励建模基准测试中取得了业界领先的性能。
NVIDIA Nemotron Nano v2 12B VL是一款强大的多模态视觉语言模型,支持多图像推理和视频理解,具备文档智能、视觉问答和摘要功能,可用于商业用途。
Tacoin
这是Tacoin基于NVIDIA GR00T模型在LIBERO libero long基准测试上进行微调的机器人操作模型。该模型采用双RGB流和8自由度状态输入,能够预测16步关节空间动作,专门用于长视野机器人操作任务。
Llama Nemotron Reranking 1B是NVIDIA开发的专门用于文本检索重排序的模型,基于Llama-3.2-1B架构微调,能够为查询-文档对提供相关性对数得分,支持多语言和长文档处理。
Llama Nemotron Embedding 1B模型是NVIDIA开发的专为多语言和跨语言文本问答检索优化的嵌入模型,支持26种语言,能够处理长达8192个标记的文档,并可通过动态嵌入大小大幅减少数据存储占用。
Nemotron-Flash-3B 是英伟达推出的新型混合小型语言模型,专门针对实际应用中的低延迟需求设计。该模型在数学、编码和常识推理等任务中展现出卓越性能,同时具备出色的小批量低延迟和大批量高吞吐量特性。
Qwen3-Nemotron-32B-RLBFF是基于Qwen/Qwen3-32B微调的大语言模型,通过强化学习反馈技术显著提升了模型在默认思维模式下生成回复的质量。该模型在多个基准测试中表现出色,同时保持较低的推理成本。
NVIDIA GPT-OSS-120B Eagle3是基于OpenAI gpt-oss-120b模型的优化版本,采用混合专家(MoE)架构,具备1200亿总参数和50亿激活参数。该模型支持商业和非商业使用,适用于文本生成任务,特别适合AI Agent系统、聊天机器人等应用开发。
RedHatAI
这是NVIDIA-Nemotron-Nano-9B-v2模型的FP8动态量化版本,通过将权重和激活量化为FP8数据类型实现优化,显著减少磁盘大小和GPU内存需求约50%,同时保持出色的文本生成性能。
Brev MCP服务器实现,使用Brev CLI的API访问令牌和当前组织配置,支持快速启动和开发调试。
Isaac Sim MCP扩展通过自然语言控制NVIDIA Isaac Sim,实现机器人模拟、场景创建和动态交互,连接MCP生态与具身智能应用。
一个基于FastMCP库的MCP服务器项目,用于通过网络客户端使用自然语言监控和远程控制Nvidia Jetson开发板。
一个基于NVIDIA USDCode API的MCP服务器,提供Isaac Sim脚本编写、USD操作、Python代码片段和API使用帮助的AI助手工具。
JetsonMCP是一个通过SSH连接管理NVIDIA Jetson Nano边缘计算设备的MCP服务器,提供AI工作负载优化、硬件配置和系统管理功能,支持自然语言指令转换为专业操作命令。
JetsonMCP是一个MCP服务器,通过SSH连接帮助AI助手管理和优化NVIDIA Jetson Nano边缘计算系统,提供AI工作负载部署、硬件优化和系统管理功能。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)