Kimi推出基于Google Nano Banana Pro模型的幻灯片生成器,提供48小时免费试用。核心功能“Agentic Slides”可自动将PDF、图片等文档转换为演示文稿,支持浏览器内直接编辑。
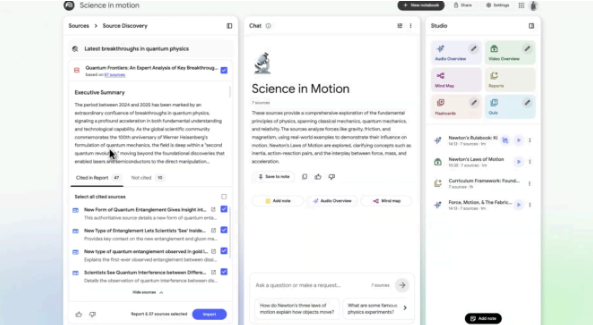
Google推出NotebookLM新工具"Deep Research",支持自动在线调研,兼容Google Sheets、Drive、PDF及Word等文件。提供快速和深度两种模式:快速模式即时返回简要来源,深度模式后台浏览数百网页生成带引用的完整报告。用户可添加其他来源,报告和引用一键保存至笔记本。功能一周内全面推送。
Anthropic公司向Pro用户开放Claude AI文件创建功能,新增支持XLSX、PDF、PPTX等Office格式。用户可通过自然语言对话直接生成和编辑文档,界面新增提示横幅,标志着该AI在生产力工具领域的重要突破。
视觉检索增强生成(Vision-RAG)与文本检索增强生成(Text-RAG)在企业信息检索中的对比研究显示,Text-RAG需先将PDF转为文本再嵌入索引,但OCR技术常导致转换不准确,影响检索效率。Vision-RAG则直接处理视觉信息,可能更高效。研究揭示了两种方法在应对海量文档时的优缺点,为企业优化搜索策略提供参考。
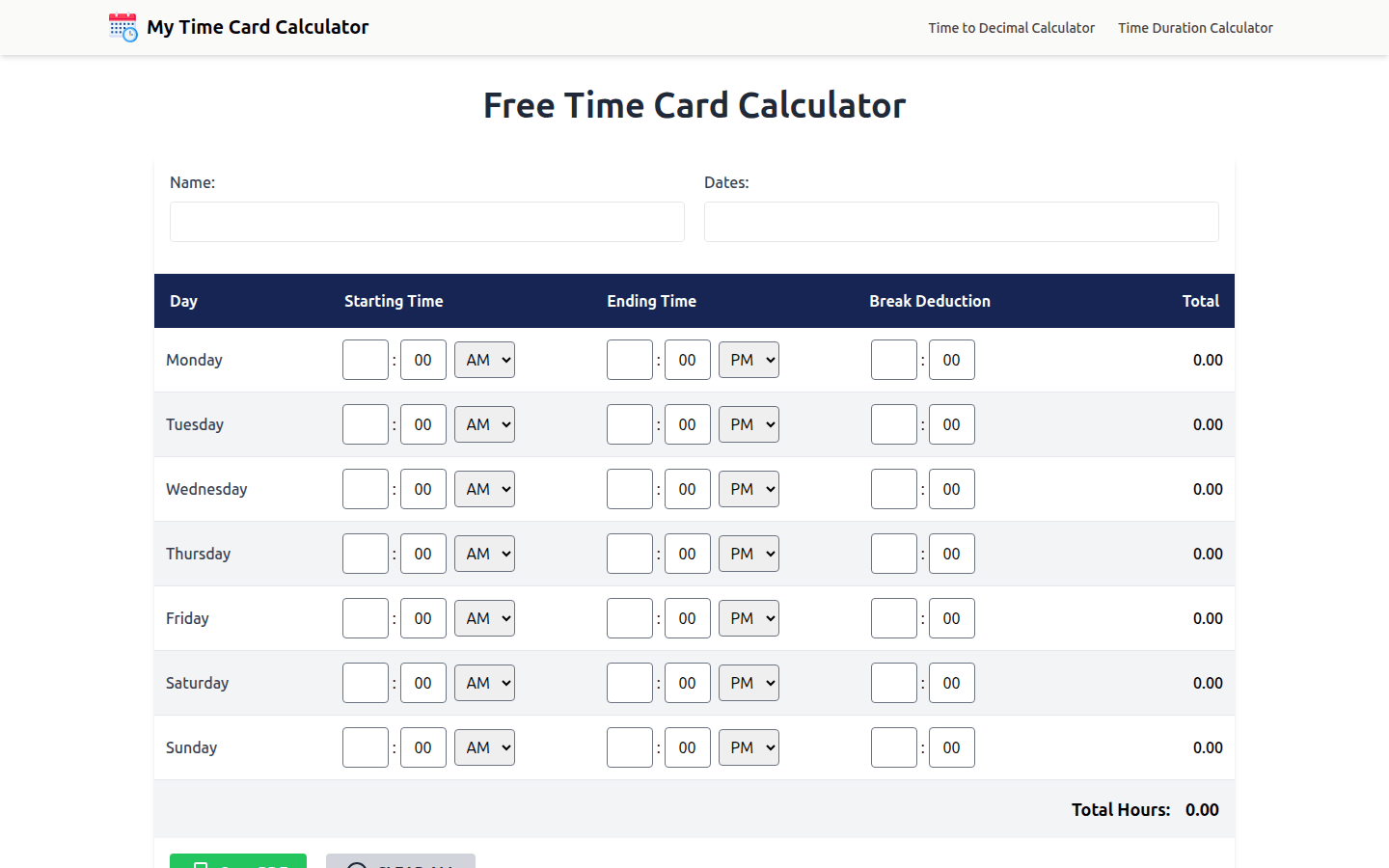
免费工时计算器,轻松计算工作时长、休息时间和每周总计,支持PDF下载。
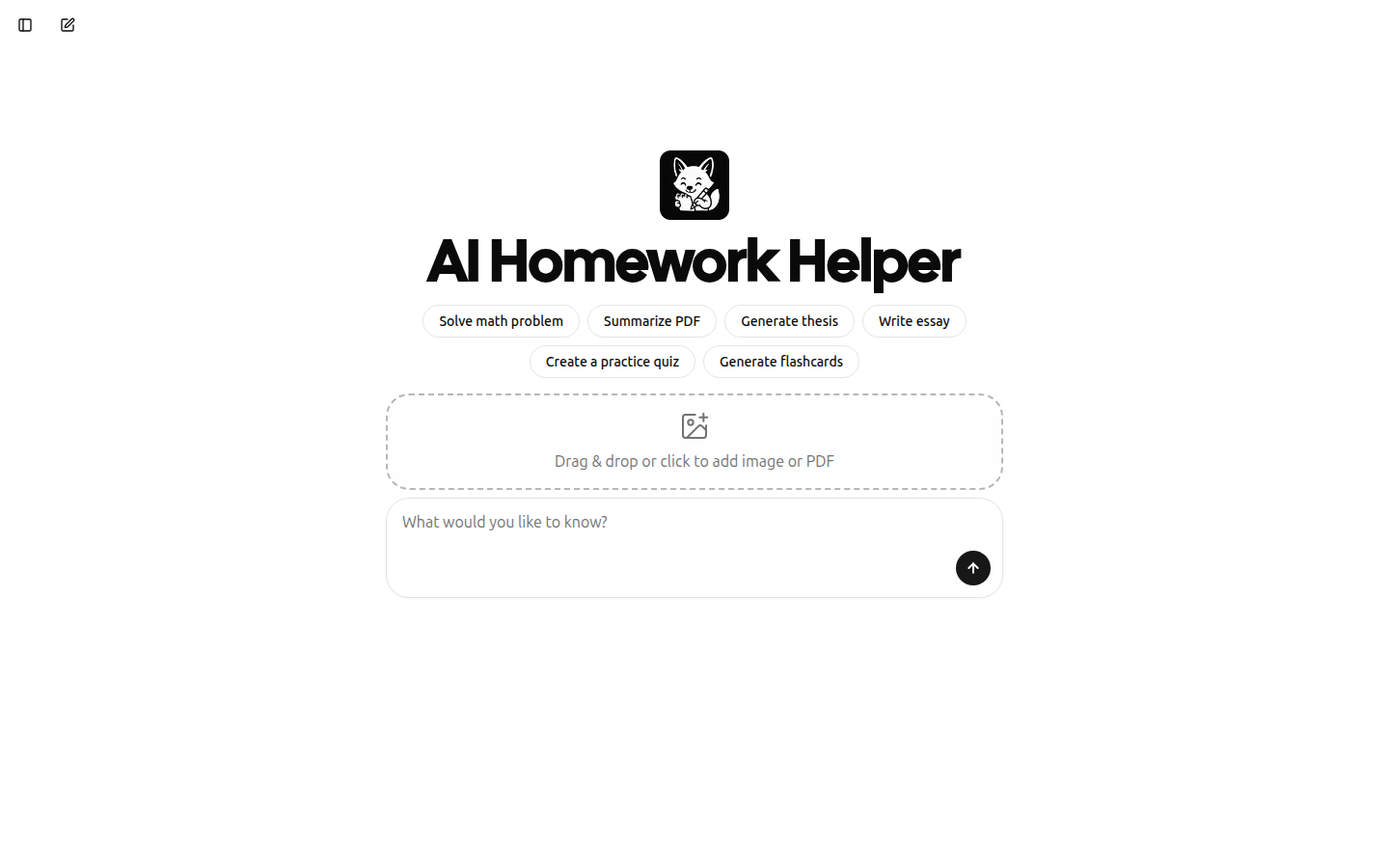
Feen AI可解决多学科作业问题,还能总结PDF、撰写论文等
免费在线工具,涵盖文本、PDF、图像等处理,免登录,快速隐私。
专为PDF而生的AI,可免费生成摘要、回答问题,支持翻译与多文件聊天。
moonshot
$1
输入tokens/百万
$8
输出tokens/百万
32k
上下文长度
TomoroAI
TomoroAI/tomoro-colqwen3-embed-4b是一款先进的ColPali风格多模态嵌入模型,能够将文本查询、视觉文档(如图像、PDF)或短视频映射为对齐的多向量嵌入。该模型结合了Qwen3-VL-4B-Instruct和Qwen3-Embedding-4B的优势,在ViDoRe基准测试中表现出色,同时显著减少了嵌入占用空间。
prithivMLmods
Chandra是一款高精度的OCR模型,能够将图像和PDF转换为结构化输出,如Markdown、HTML和JSON,同时保留详细的布局信息。支持40多种语言,擅长处理复杂的文档元素。
noctrex
LightOnOCR-1B-1025的量化版本,专门用于图像转文本任务,在文档理解、视觉语言处理等领域有广泛应用。该模型支持多种欧洲语言,适用于OCR、PDF处理和表格识别等场景。
Mungert
Nanonets-OCR2-3B GGUF模型是专为文档处理设计的强大工具,能够将各类文档智能转换为结构化的Markdown格式,具备OCR、图像转文本、PDF转Markdown以及视觉问答等多种先进识别和处理能力。
datalab-to
Chandra是一款先进的OCR模型,能够从图像和PDF中高精度提取文本并保留布局信息。它支持Markdown、HTML和JSON格式输出,在手写体识别、表单重构、表格处理等方面表现出色,支持40多种语言。
echo840
MonkeyOCR是一款基于结构-识别-关系(SRR)三元范式的文档解析模型,能够高效处理PDF和图像文档,提取文本、公式、表格等结构化内容,支持中英文文档解析。
Adun
olmOCR是一款基于Qwen2-VL-7B-Instruct微调的光学字符识别模型,专注于将PDF等图像内容转换为文本,并通过微调提升特定场景下的识别准确率。
apkonsta
专为国际财务报告准则(IFRS)PDF文档优化的表格检测模型,擅长处理无边框表格
kitjesen
该模型能够将PDF文档转换为Markdown格式,保持原始文档排版结构,准确识别数学公式和表格。
shixuanleong
VisualHeist是一个目标检测模型,专门用于从PDF文件中提取图表、示意图和表格,包括标题、页眉和页脚。
HongxuanLi
Nougat是基于Donut架构的视觉-语言模型,专为将科学类PDF转录为Markdown格式而设计。
hantian
一款阅读顺序预测模型,可将从PDF提取或通过OCR检测的文本框转换为可读顺序。
Xenova
Nougat是一个基于视觉的学术文档理解模型,能够将科学PDF图像转换为Markdown格式文本。
facebook
Nougat是基于Donut架构的视觉-语言模型,专为将科学PDF转换为Markdown格式而设计。
Nougat是基于Donut架构的模型,专为将科学PDF转录为易用Markdown格式而训练
shubh1608
基于图像文件夹数据集训练的OCR模型,用于PDF文档的文本识别
impira
基于LayoutLM架构微调的文档分类模型,专门用于处理PDF文档特别是发票的分类任务
geralt
基于100多本机械/汽车类PDF书籍文本微调的蒸馏版GPT-2模型,专注于机械工程领域的文本生成任务
Markdownify是一个多功能文件转换服务,支持将PDF、图片、音频等多种格式及网页内容转换为Markdown格式。
本项目构建了一个基于IBM Watsonx.ai的检索增强生成(RAG)服务器,使用ChromaDB进行向量索引,并通过模型上下文协议(MCP)暴露接口。该系统能够处理PDF文档并基于文档内容回答问题,实现了将大型语言模型与特定领域知识相结合的智能问答功能。
Upstage MCP Server是一个连接AI助手与Upstage AI文档处理API的服务器,支持从PDF、图片和Office文件中提取结构化内容,并集成Claude Desktop等MCP客户端。
一个基于模型上下文协议(MCP)的服务器,提供美国国家综合癌症网络(NCCN)临床指南的访问服务。该系统通过直接读取指南PDF内容而非使用RAG技术,确保医疗指导的准确性和可靠性。
基于MCP的高性能PDF转Markdown服务,支持本地文件和URL批量处理,保留文档结构并智能优化输出。
一个将Markdown文档转换为PDF文件的MCP服务器,支持语法高亮和自定义样式
MCP服务器PDF处理服务
一个基于FastAPI的MCP服务器,自动抓取、总结并推送Reddit内容到Slack。系统利用Azure OpenAI生成精选子版块帖子的摘要,整理为PDF报告并分享给团队。
该项目是一个集成了多种功能的MCP服务器套件,包含媒体工具、信息检索、PDF生成和演示文稿创建等服务,需分别配置运行。
该项目构建了一个基于RAG的HR聊天机器人,通过MCP服务器作为功能调用中心,实现PDF文档上传、解析、检索及自然语言问答功能。
一个为Claude Desktop提供文档操作功能的MCP服务器,支持Word、Excel和PDF文件的创建、编辑与格式转换。
Deep Research是一个基于代理的工具,提供网页搜索和高级研究功能,支持PDF分析、图像描述和YouTube转录提取,可作为MCP服务器运行。
该项目是一个基于FastMCP的USPTO专利数据访问服务器,支持通过专利公共搜索API和开放数据门户API获取美国专利商标局的专利和专利申请数据,为Claude Desktop等MCP客户端提供专利搜索、全文获取、PDF下载和元数据查询功能。
一个基于MCP协议的PDF阅读服务,支持从本地文件和URL提取文本内容,提供错误处理和标准化输出。
一个基于Model Context Protocol的arXiv论文检索服务,提供搜索、获取论文详情、按分类检索及PDF全文提取功能。
一个基于MCP协议的PDF工具服务器,提供合并、提取等PDF操作功能
一个基础的MCP服务器,用于与PDF和EPUB文档交互。
PDF内容提取服务
一个支持MCP协议的PDF阅读工具,通过MCP服务器提供read_pdf功能读取PDF文档,适用于Claude Desktop等MCP支持的AI工具。
 Transformers其他
Transformers其他%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)