蚂蚁集团开源多智能体协作基础设施Avernet V0.1,解决大模型应用中多智能体协作效率低这一核心痛点。该项目专注构建协作层,不替代智能体自身推理能力,为复杂任务自动化处理提供基础支持。
Deep Code开源终端编程助手因深度适配DeepSeek-V4系列模型受关注,主打高质量推理与代码生成。历经迭代至v0.1.31版,功能趋于成熟,支持VS Code插件模式,为开发者提供新的辅助选择。
小米技术团队开源了AI编程助手MiMo Code V0.1.0,基于OpenCode二次开发,采用MIT协议,允许自由修改和商业集成。该工具主打“模型Agent协同优化”,核心亮点包括独创持久记忆系统,解决传统AI编码工具的“健忘”问题,旨在突破局限,实现自进化。
腾讯云Agent平台QClaw发布v0.2.14版本,这是迄今最大更新。升级包括接入Hermes框架,支持创建运行Hermes类型Agent,实现底层模型多元化,大幅降低AI使用门槛,用户可在单一应用内调度多种模型。
Grok Imagine v0.9可快速生成图像和视频,有稳定运动、清晰视觉和音频同步。
一键从网页复制真实组件,添加到Lovable、Bolt或V0,快速构建
停止在混乱的构建中浪费信用。VibeBlocks是一个简单的免费工具,利用人工智能将模糊的应用想法转化为结构化的基于规范的蓝图,您可以复制粘贴到Lovable、Cursor、Bolt.new、v0和Replit中。
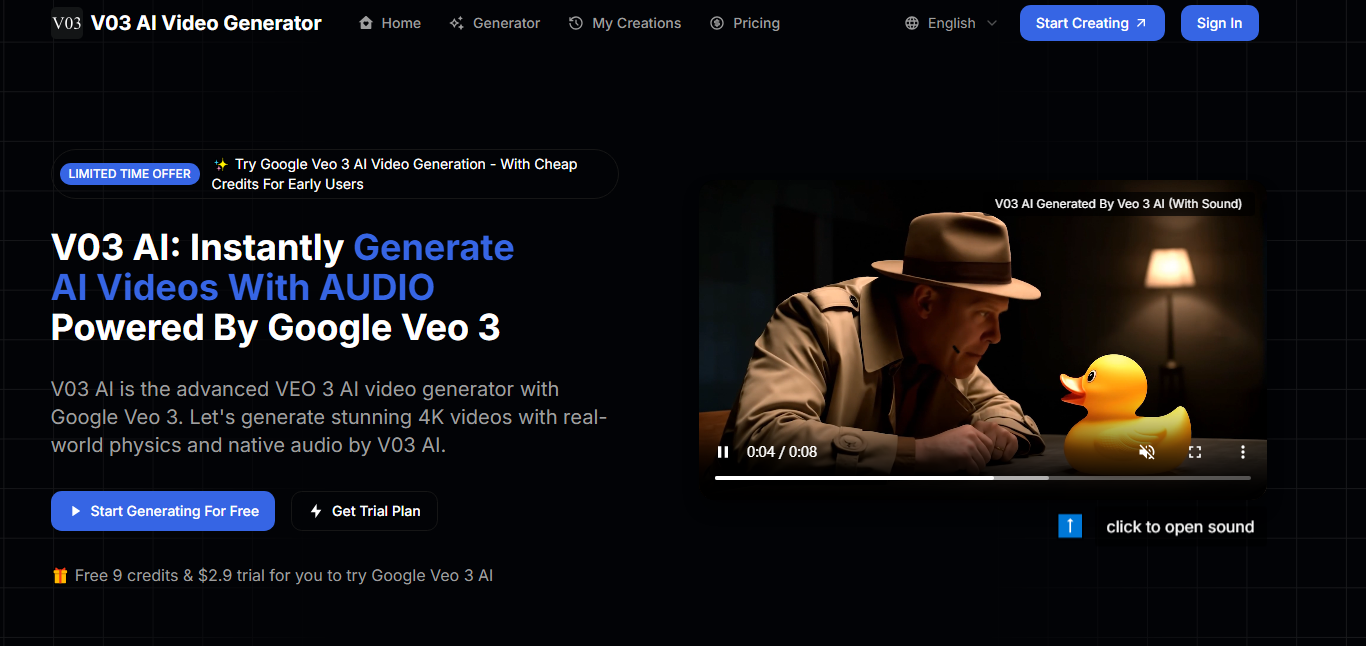
V03 AI是基于Google Veo 3 AI技术的视频生成器,支持文本到视频和图片到视频的转换,具备音频功能。
gia-uh
塞西莉亚FT MS v1是基于塞西莉亚2B v0.1微调的古巴语言模型,专门针对古巴西班牙语进行优化,捕捉古巴语言、文化和社会的细微差别。该模型支持西班牙语和英语,主要用于文本生成任务。
lapa-llm
Lapa LLM v0.1.2是基于Gemma-3-12B开发的乌克兰语处理开源大语言模型,专注于乌克兰语的自然语言处理任务,在乌克兰语处理方面表现出卓越性能。
nineninesix
KaniTTS Pretrain v0.3是一款高速、高保真的文本转语音模型,专为实时对话式人工智能应用优化,采用两阶段管道架构,结合大语言模型和高效音频编解码器,实现极低延迟和高品质语音合成。
ggml-org
Ultravox v0.5是基于Llama-3 2.1B架构优化的音频文本转文本模型,专注于高效处理语音转写任务。
2121-8
基于sarashina2.2‑0.5b‑instruct‑v0.1训练的日语TTS模型,支持通过提示控制音质
terminusresearch
AuraFlow v0.3 是一个完全开源的基于流的文本生成图像模型,支持多种宽高比,最高可达1536像素。
NAMAA-Space
QARI-OCR v0.3 是一款专注于阿拉伯语结构化文档理解的光学字符识别视觉语言模型,基于 Qwen2-VL-2B-Instruct 构建,擅长保留文档布局和格式。
DevQuasar
OpenHands LM 32B v0.1 是一个32B参数规模的开源大语言模型,致力于知识的自由传播。
matrixportalx
Turkish Llama 8B Instruct v0.1 是一个专门针对土耳其语优化的指令调优语言模型,基于Llama-3架构开发。该模型在土耳其语文本生成和理解方面表现出色,特别擅长处理土耳其文化相关的语境和表达。
sometimesanotion
Lamarck 14B v0.7是一款注重多步推理、散文写作和多语言能力的通用融合模型,14B参数级模型追求全面均衡的表现。
nintwentydo
Razorback 12B v0.2 是一个结合了Pixtral 12B和UnslopNemo v3优势的多模态模型,具备视觉理解和语言处理能力。
EVA-UNIT-01
EVA LLaMA 3.33 70B v0.1 是一个专注于角色扮演和故事写作的专业大语言模型,基于Llama-3.3-70B-Instruct进行全参数微调。通过使用合成数据与自然数据的混合训练集,该模型在通用性、创造性和独特风格方面有显著提升,特别擅长长上下文理解和减少重复内容。
EVA LLaMA 3.33 70B v0.0 是一款专注于角色扮演和故事创作的专业大语言模型,基于 Llama-3.3-70B-Instruct 进行全参数微调,使用了合成数据和自然数据的混合数据集,显著提升了模型的通用性、创造性和独特风格。
Ray2333
该奖励模型在reward-bench上获得了92.6分,是基于GRM-Llama3.1-8B-sftreg模型使用去污染的Skywork偏好数据集v0.2微调而成。
EVA Qwen2.5-72B v0.1是基于Qwen2.5-72B进行全参数微调的专业角色扮演和故事写作模型。该模型在合成数据和自然数据的混合数据集上训练,专注于提升角色扮演和创意写作能力,在指令遵循、长上下文理解和整体连贯性方面表现出色。
dataautogpt3
Proteus v0.6是基于SDXL架构的AI图像生成模型,经过全面重构后专注于提升图像的真实感。这是重构后的首个版本,采用多视角融合技术训练,能够生成高质量的逼真图像。
AIDX-ktds
ktdsbaseLM v0.11 是基于 OpenChat 3.5 的韩语大语言模型,专注于理解韩语及韩国多元文化,适用于多种自然语言处理任务。
v000000
Qwen2.5-Lumen-14B是基于Qwen2.5-14B-Instruct微调得到的文本生成模型,专门针对故事写作和角色扮演场景进行了优化。该模型通过偏好微调实现了更好的指令遵循能力,在文学创作和对话生成方面表现优异。
flowaicom
Flow Judge v0.1 是一款轻量级但功能强大的 38 亿参数模型,可在多个领域对大语言模型(LLM)系统进行定制化评估。
fal
一个用于捕获v0.dev AI生成内容的工具
该项目是基于官方v0.8.1版本修改的MCP Java SDK,主要进行了代码适配和依赖降级,以支持Java 8、Spring Boot 2.x和Solon 3.x等旧版本环境。
一个基于MCP协议的服务器,可将本地或剪贴板中的图片上传至私有S3存储桶并返回预签名访问URL,便于下游工具(如v0)调用。
一个简易的MCP v0.2客户端和服务端实现项目,用于学习MCP协议,非生产用途。
 Transformers
Transformers%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)