LangChain是一个基于语言模型的平台,用于构建和部署使用RAG技术的大模型应用。它包括查询转换、假设文档嵌入(HyDE)、路由机制、查询构建与索引策略、检索技术,以及最终的生成阶段。
最近,LangChain实现了RAG(检索增强型生成)的指南,为用户提供了学习如何使用LangChain构建和部署RAG技术的大模型应用的详细教程。通过这个指南,用户可以了解如何利用LangChain和RAG技术构建自己的应用,从而实现更高效的信息检索和生成。

LangChain是一个基于语言模型的平台,用于构建和部署使用RAG技术的大模型应用。它包括查询转换、假设文档嵌入(HyDE)、路由机制、查询构建与索引策略、检索技术,以及最终的生成阶段。
最近,LangChain实现了RAG(检索增强型生成)的指南,为用户提供了学习如何使用LangChain构建和部署RAG技术的大模型应用的详细教程。通过这个指南,用户可以了解如何利用LangChain和RAG技术构建自己的应用,从而实现更高效的信息检索和生成。
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。

《自然》杂志研究显示,2024年生物医学论文中AI写作痕迹显著:PubMed 150万篇摘要中,超20万篇含AI特征词(如华丽形容词)。非英语国家使用率更高(中国、韩国达15%),低门槛期刊飙升至24%。作者开始规避典型AI词汇,转向通用表达。研究团队分析1400万篇摘要,发现AI正深度影响学术写作风格,呼吁建立规范确保科研严谨性。未来需进一步评估AI对学术文献的实际影响。

大型语言模型(LLM)通过结合任务提示和大规模强化学习(RL)在复杂推理任务中取得了显著进展,如 Deepseek-R1-Zero 等模型直接将强化学习应用于基础模型,展现出强大的推理能力。然而,这种成功在不同的基础模型系列中难以复制,尤其是在 Llama 系列上。这引发了一个核心问题:究竟是什么因素导致了不同基础模型在强化学习过程中表现不一致?强化学习在 Llama 模型上的扩展限制OpenAI 的 o1、o3和 DeepSeek 的 R1等模型在竞赛级数学问题上通过大规模强化学习取得了突破,推动了对千亿参数以下小

淘天集团昨日在其“硬核少年技术节4.0”活动上宣布,其自主研发的百亿参数推荐大模型RecGPT已正式上线。这一创新成果将全面升级手机淘宝首页的“猜你喜欢”信息流,通过AIGR(生成式推荐)技术,为用户带来更加精准、个性化的推荐体验。RecGPT的上线,标志着淘宝在电商推荐领域迈出了重要一步。测试数据显示,搭载RecGPT大模型的推荐信息流表现出色,用户点击量实现两位数增长,同时用户加购次数和停留时长也均提升了超过5%。这表明RecGPT在提升用户互动和转化效率方面取得了显著
随着企业加速采用人工智能技术,如何有效管理复杂的AI工作流程成为关键挑战。最新行业分析指出,建立稳健的AI编排层是解决"提示词混乱"问题的有效方案。 AI编排框架的选择困境 当前市场上存在多种AI编排工具和框架,包括LangChain等知名解决方案,这给企业技术选型带来挑战。
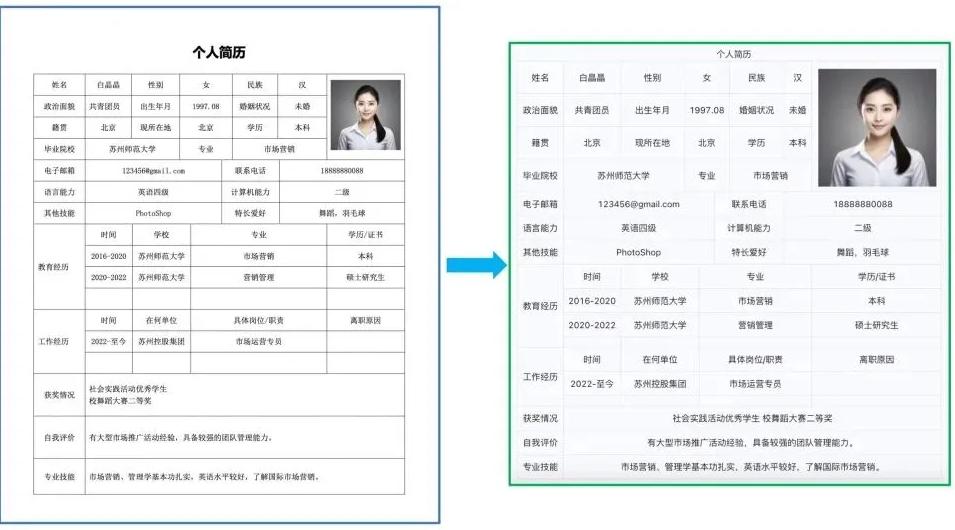
近日,随着大模型与RAG技术的迅猛发展,结构化数据在智能系统中的价值愈发凸显。在此背景下,如何将文档图像、PDF等非结构化数据精准转换为结构化数据,成为行业亟待攻克的关键难题。针对此现状,飞桨团队凭借深厚的技术积累和对用户需求的深刻洞察,推出新一代文档解析工具——PP-StructureV3,为解决复杂文档解析难题提供了创新方案。 当前,众多开源方案在处理复杂文档时面临诸多挑战,如文字识别不准确、阅读顺序恢复混乱、表格及公式识别效果差等。这些问题严重制约了大模型训练微调的数据质量及AI应用的落地进程。而PP-StructureV3的诞生,正是为了打破这一僵局,为行业带来高效、精准的文档解析体验。

一款名为 Kimi-Dev-72B 的开源代码大型语言模型(LLM)现已推出,旨在革新软件工程领域的问题解决方式。该模型在 SWE-bench Verified 基准测试中展现出最先进的性能,尤其擅长自主修复 Docker 环境中的真实代码仓库。Kimi-Dev-72B 的核心优势在于其通过大规模强化学习进行优化。它能够独立识别并修复代码缺陷,并在整个测试套件通过时获得奖励,从而确保所提供的解决方案不仅正确,而且鲁棒。该项目已在 Hugging Face 和 GitHub 上开源,开发者可以自由下载和部署。Kimi-Dev-72B 提供了一个简化的两阶

近日,一款名为RAGFlow的开源RAG(检索增强生成)引擎引发了业界广泛关注。这款基于深度文档理解的企业级AI工具,以其强大的多模态数据处理能力和高效的工作流程,为企业处理复杂文档和实现精准问答提供了全新解决方案。RAGFlow:深度文档理解的先锋RAGFlow是一款完全开源的RAG引擎,专注于深度文档理解,旨在帮助企业和个人从海量非结构化数据中提取有价值的信息。不同于传统基于关键词的检索方式,RAGFlow结合大型语言模型(LLM)与先进的文档解析技术,支持从复杂格式的文档(如Wor

近日,小红书的 hi lab 团队正式推出了其首个开源文本大模型 ——dots.llm1。这一新模型以其卓越的性能和庞大的参数量引起了业界的广泛关注。dots.llm1是一款大规模的混合专家(MoE)语言模型,拥有惊人的1420亿个参数,其中激活参数达到140亿。经过11.2TB 的高质量数据训练,这款模型的性能可以与阿里巴巴的 Qwen2.5-72B 相媲美。这意味着 dots.llm1不仅在文本生成方面具有极高的准确性和流畅度,还能支持更复杂的自然语言处理任务。值得注意的是,这一模型的预训练过程并没有使用合成数据,

最近,苹果公司发布了一篇引发热议的论文,指出当前的大语言模型(LLM)在推理方面存在重大缺陷。这一观点迅速在社交媒体上引起热议,尤其是 GitHub 的高级软件工程师 Sean Goedecke 对此提出了强烈反对。他认为,苹果的结论过于片面,并不能全面反映推理模型的能力。苹果的论文指出,在解决数学和编程等基准测试时,LLM 的表现并不可靠。苹果研究团队采用了汉诺塔这一经典的人工谜题,分析了推理模型在不同复杂度下的表现。研究发现,模型在面对简单谜题时表现较好,而在复杂度

随着大语言模型(LLM)技术的迅猛发展,文档解析领域迎来了一位新星——MonkeyOCR。这款轻量级文档解析模型以其卓越的性能和高效的处理速度,迅速成为业界关注的焦点。MonkeyOCR:小模型,大能量MonkeyOCR以仅3B参数的轻量级架构,在英文文档解析任务中展现出惊艳的性能。根据社交媒体上的最新讨论,MonkeyOCR在多项文档解析任务中超越了Gemini2.5Pro和Qwen2.5-VL-72B等重量级模型,平均性能提升显著。尤其是在复杂文档类型的解析上,MonkeyOCR表现尤为突出,公式解析提升高达15.0%,表格解析提升8