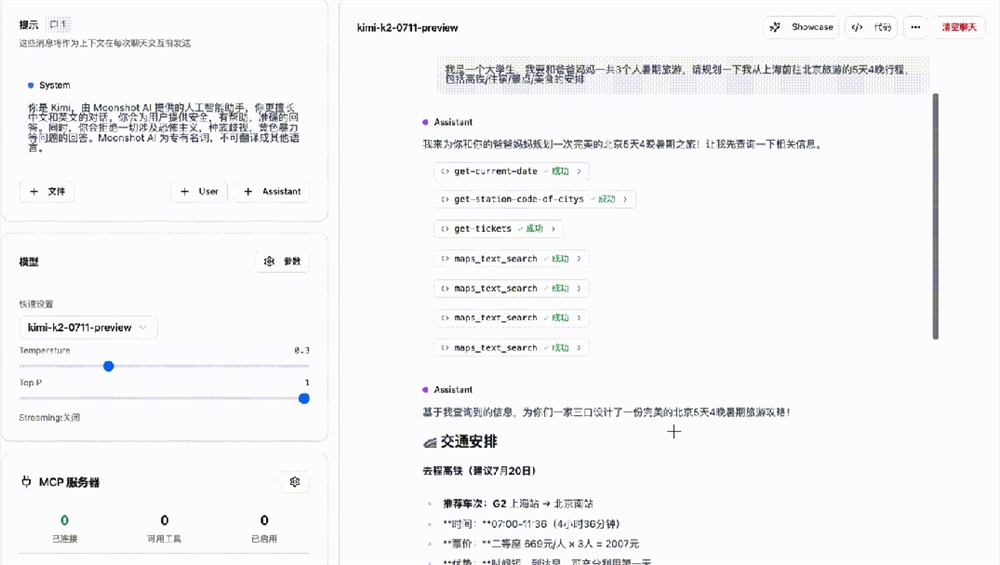
はじめに
現代のユーザーインターフェースデザインにおいて、ユーザーエクスペリエンスの最適化は常に追求される目標です。ComyUIは、大規模言語モデルを統合した先進的なユーザーインターフェースであり、ユーザーがより効率的にタスクを完了できるよう支援します。この記事では、ComyUI上で大規模言語モデルを利用してプロンプトを逆推測し、ユーザーインタラクションの円滑さと効率性を向上させる方法について詳しく説明します。
ステップ1:Ollamaのダウンロードとインストール
Ollamaは、ユーザーがローカルデバイス上で大規模言語モデル(LLM)を実行できるようにすることを目的とした、オープンソースの大規模言語モデルサービスツールです。
Ollama公式サイトからOllamaをダウンロードします:https://ollama.com/
お使いのシステムに合わせてダウンロードしてインストールしてください。

Ollamaモデルをダウンロードします。公式サイトの右上にある「models」をクリックすると、多くのモデルが表示されます。ここでは、llava-phi3モデルを例に、モデルのインストール方法を説明します。llava-phi3はビジョンモデルであり、画像からプロンプトを生成できます。非常に便利です。

llava-phi3のホームページで「ollama run llava-phi3:latest」というコマンドをコピーします。

Ollamaがインストールされ、実行されていることを確認してください。

次に、CMDコマンドプロンプトウィンドウを開き、コピーしたコマンドを貼り付けます。Ollamaは自動的にモデルをダウンロードして呼び出します。

メッセージを送信して会話ができるようになれば、インストールは成功です。

ステップ2:ComfyUI Ollamaプラグインのダウンロード
マネージャーでollamaを検索してインストールします。
または、Git URLを使用してインストールすることもできます:https://github.com/stavsap/comfyui-ollama

ステップ3:ComfyUIでOllamaを使用する
インストールが完了したら、ollama Visionノードを使用して、提供された画像に基づいてプロンプトを生成できます。

例:SD3またはKolorsなど、意味理解能力の高いモデルを使用している場合、このプラグインは非常に便利です。SD1.5またはSDXLを使用している場合は、WD1.4タグを使用してプロンプトを逆推測できます。

まとめ
上記のステップに従うことで、ComyUI上で大規模言語モデルを利用してプロンプトを効果的に逆推測し、ユーザーエクスペリエンスを向上させることができます。
------------------------------------------------------------------------------------------
站長素材AIチュートリアルは、站長之家が運営するAIイラストチュートリアルプラットフォームです。
多数のAI無料チュートリアルを提供しており、継続的に有益なコンテンツを更新しています。