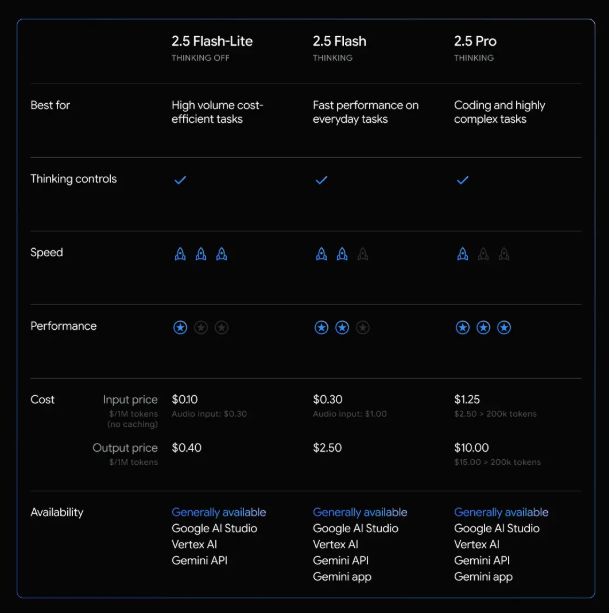
先日東京で開催されたGemma開発者向けイベントで、Googleは新しい日本語版Gemma AIモデルを発表しました。このモデルはGPT-3.5に匹敵する性能を持ちながら、パラメータ数はわずか20億とコンパクトで、モバイル機器上での動作に最適です。
")
今回発表されたGemmaモデルは、日本語処理において優れた性能を発揮し、英語処理能力も維持しています。小型モデルでは、新しい言語への微調整時に「壊滅的な忘却」と呼ばれる、以前学習した情報が上書きされる問題が発生する可能性がありますが、Gemmaはこの問題を克服し、強力な言語処理能力を備えています。
さらに特筆すべきは、GoogleがKaggleやHugging Faceなどのプラットフォームを通じて、モデルの重み、トレーニングデータ、サンプルコードをすぐに公開し、開発者の早期導入を支援している点です。これにより、開発者はこのモデルを容易にローカル環境で利用でき、特にエッジコンピューティングアプリケーションにおいて、多くの可能性を生み出します。
Googleは、より多くの国際的な開発者を支援するため、「グローバルコミュニケーションとGemmaの解き放ち」というコンテストも開催し、賞金は15万ドルに上ります。このプログラムは、開発者がGemmaモデルを自国の言語に適応させることを支援することを目的としています。現在、アラビア語、ベトナム語、ズールー語のプロジェクトが進行中で、インドでは「Navarasa」プロジェクトとして12種類のインド言語に対応するモデルの最適化が進められており、別のチームでは韓国語の方言に対応するための微調整が研究されています。
Gemma2シリーズモデルは、少ないパラメータで高い性能を実現することを目指しています。Metaなどの他社の同様のモデルと比較しても、Gemma2は優れた性能を示し、場合によっては、パラメータ数2億のGemma2が、LLaMA-2など700億パラメータのモデルを上回ることもあります。
開発者や研究者は、Hugging Face、Google AI Studio、Google Colabの無料プランを通じてGemma-2-2Bモデルおよびその他のGemmaモデルを入手でき、Vertex AI Model Gardenでも見つけることができます。
公式サイト:https://aistudio.google.com/app/prompts/new_chat?model=gemma-2-2b-it
Hugging Face:https://huggingface.co/google
Google Colab:https://ai.google.dev/gemma/docs/keras_inference?hl=de
要点:
🌟 Googleが新しい日本語版Gemma AIモデルを発表。GPT-3.5に匹敵する性能で、パラメータ数はわずか2億とコンパクト。モバイル機器での動作に最適。
🌍 Googleが「グローバルコミュニケーションとGemmaの解き放ち」コンテストを開催。賞金15万ドルで、地域言語版の開発を支援。
📈 Gemma2シリーズモデルは、少ないパラメータで高い性能を実現。より大きなモデルを上回る場合もあり、開発者の可能性を広げる。