SDコミュニティは、静止画を動画に変換するI2V-Adapterプラグインを発表しました。革新的なアダプターモジュールにより、学習パラメータが削減され、動画の品質が向上します。
実験により、時間的整合性、ID情報の保持、フレーム間の類似性において顕著な成果が得られ、I2V分野に新たな創造的な応用可能性をもたらすことが実証されました。
SDコミュニティは、静止画を動画に変換するI2V-Adapterプラグインを発表しました。革新的なアダプターモジュールにより、学習パラメータが削減され、動画の品質が向上します。
実験により、時間的整合性、ID情報の保持、フレーム間の類似性において顕著な成果が得られ、I2V分野に新たな創造的な応用可能性をもたらすことが実証されました。
【AIデイリー】へようこそ!ここは、毎日人工知能の世界を探求するためのガイドです。毎日、開発者に焦点を当て、技術トレンドを洞察し、革新的なAI製品アプリケーションを理解するのに役立つ、AI分野のホットなコンテンツをお届けします。

淘宝天猫は正式に、商品画像から映像を生成するAIツール「図生ビデオ」を導入しました。これは618大型プロモーションアクティビティに備えるためです。この機能の特徴は、商家が商品画像をアップロードするだけで、最長20秒の短編ビデオを自動生成できることです。この技術により商家はコンテンツ制作の効率が大幅に向上し、毎月数千元のコストを削減し、制作期間が10日以上短縮されました。「図生ビデオ」機能は淘宝が提供する商家向けの新しいAIGC(人工知能生成コンテンツ)製品です。


先日、Meta Reality Labsの研究チームは、一枚の任意に撮影された写真から、最大1000ピクセルの高解像度の密集した回転ビデオを生成できる革新的な生成モデル「Pippo」を発表しました。この画期的な技術は、コンピュータビジョンと画像生成分野における重要な進歩を示しています。Pippoモデルの中核は、その多視点拡散変換器のデザインにあります。従来の生成モデルとは異なり、Pippoは追加の入力、例えば適合パラメータなどを必要としません。

最近のAI分野のブームは、すべての企業に恩恵をもたらしたわけではなく、一部のスタートアップ企業は依然として生き残りを模索しています。AIベースのパーキングプラットフォームであるMetropolisは、AnyVisionとして知られていた物議を醸すコンピュータビジョン企業Oostoを買収しました。この取引は全株式取引で、1億2500万ドルと評価されており、Oostoが長年にわたって投資家から調達した3億8000万ドルをはるかに下回り、ピーク時の評価額よりも低いことは明らかです。Metropolisの技術は…

近年、人工知能とコンピュータビジョンの技術の急速な発展に伴い、人間とコンピュータ間のインタラクションはますます生き生きとして表現力豊かになっています。特にアニメーション制作分野において、静止画像から動的ビデオを生成する方法は研究のホットトピックでした。最近、"DisPose"という新しい技術が登場し、ポーズの分離によるガイドによって、より制御可能な人物画像アニメーションを実現しました。簡単に言うと、DisPoseは入力動作ビデオと参照人物を入力することで、参照人物にビデオ内の動作をさせることができます。

北京TuSimple未来科技有限公司は、2024年12月17日、同社初の画像からビデオを生成する大規模言語モデル「如意」を発表し、Ruyi-Mini-7Bバージョンをオープンソース化しました。ユーザーはhuggingfaceプラットフォームからダウンロードして使用できます。2015年設立のTuSimpleは、カリフォルニア州サンディエゴに本社を置く企業で、アニメーションゲームや交通運輸業界など、複数の業界におけるAI技術の応用を専門としています。

先日、OpenAIは競合他社であるGoogle DeepMindから3名のベテランコンピュータビジョンおよび機械学習エンジニアを採用し、人工知能分野における研究開発能力をさらに強化すると発表しました。新たに採用された3名のエンジニアは、Lucas Beyer氏、Alexander Kolesnikov氏、Xiaohua Zhai氏で、スイス・チューリッヒの新オフィスで勤務します。OpenAI幹部は火曜日の社内メモでこのニュースを伝え、次のように述べています。

近年、コンピュータビジョンとアニメーション技術の急速な発展に伴い、生き生きとしたヒューマンアニメーションの生成が研究のホットトピックとなっています。最新の研究成果であるEchoMimicV2は、参照画像、音声セグメント、ジェスチャーシーケンスを利用して、高品質の半身ヒューマンアニメーションを作成します。簡単に言うと、EchoMimicV2は1枚の画像+1つのジェスチャー動画+1つの音声セグメントを入力することで、新しいデジタルヒューマンを生成できます。入力された音声内容は、入力されたジェスチャーとヘッドモーションを含む動画となります。EchoMimicV2の開発は
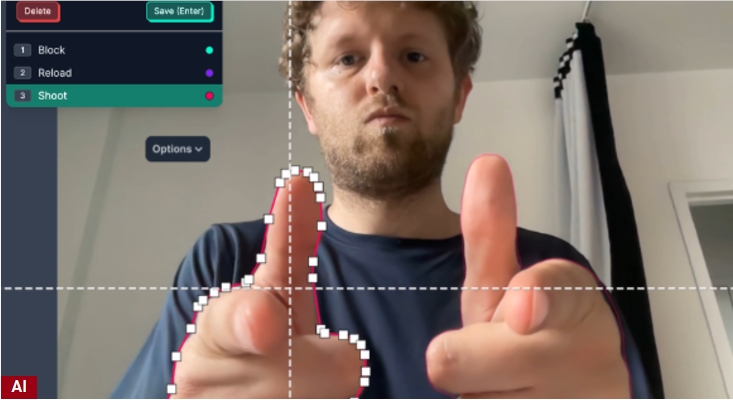
ビジョンAI開発プラットフォームのRoboflowは最近、4000万ドルのシリーズB資金調達完了を発表しました。このラウンドはGVがリードし、Craft Ventures、Y Combinator、さらにVercel AIの創設者Guillermo Rauch氏、Google幹部のJeff Dean氏、Replitの創設者Amjad Masad氏など著名な投資家が参加しました。ワンストップのビジョンAI開発プラットフォームとして、Roboflowはコンピュータビジョンモデルの開発を再定義しています。

北京智源人工知能研究院(BAAI)は最近、画期的な新たな万能ビジュアル生成モデルOmniGenを発表しました。OmniGenモデルは、その統一性、簡潔性、そしてクロス・タスク知識転移能力が特徴で、テキストから画像生成、画像編集、テーマ主導型生成、ビジュアル条件付き生成など、複数の画像生成タスクを単一のフレームワーク内で処理できます。さらに、OmniGenは画像ノイズ除去やエッジ検出などの古典的なコンピュータビジョンタスクも処理可能です。