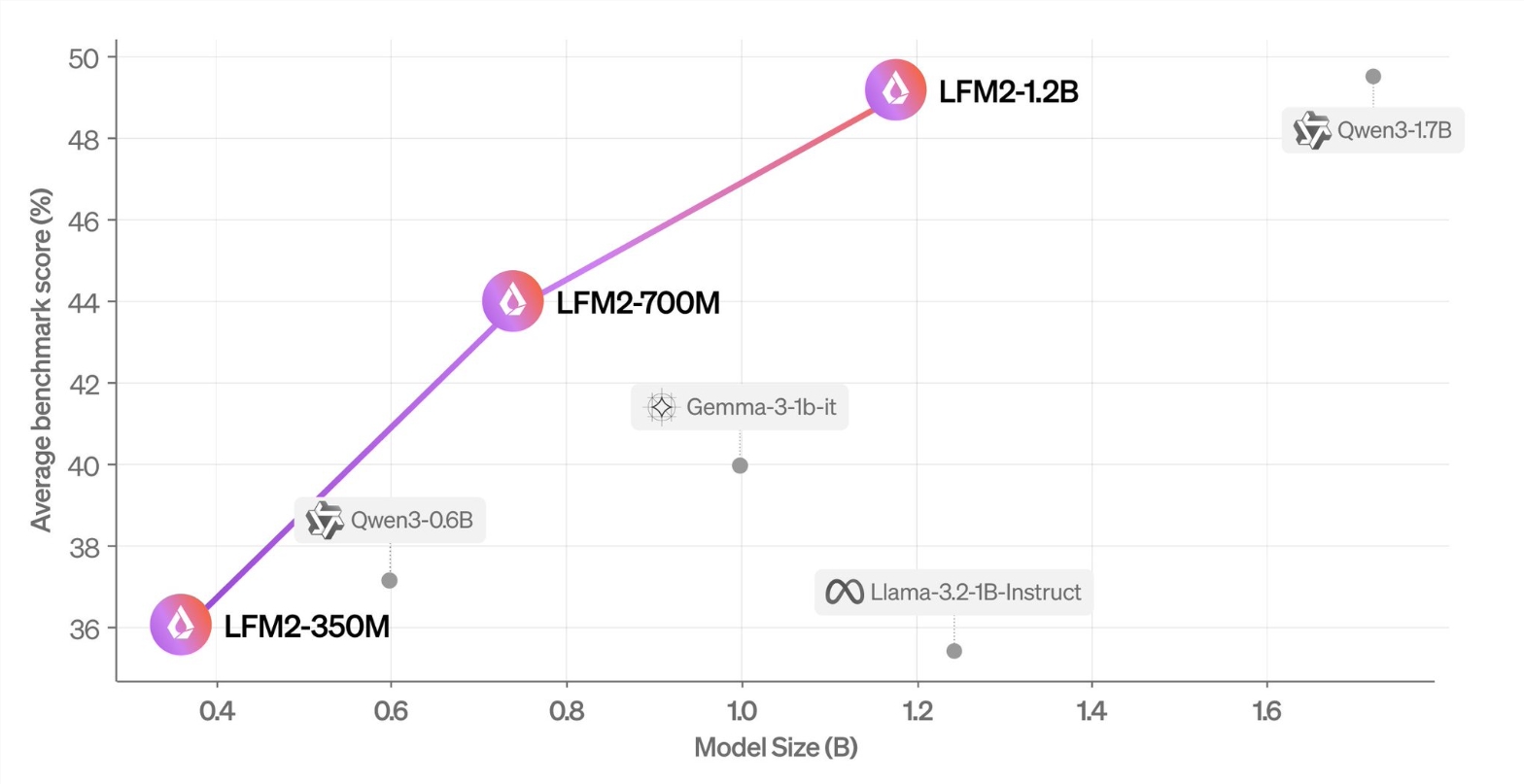
Recently, the Speech Team at Qwen Lab has achieved a milestone in spatial audio generation by introducing the OmniAudio technology, which can directly generate First-order Ambisonics (FOA) audio from 360° videos, opening up new possibilities for virtual reality and immersive entertainment.
As a technology that simulates real auditory environments, spatial audio enhances immersive experiences. However, existing technologies are mostly based on fixed-perspective videos and fail to fully utilize the spatial information of 360° panoramic videos. Traditional video-to-audio generation techniques mainly produce non-spatial audio, failing to meet the demands of immersive experiences for 3D sound localization. Moreover, they are often based on limited-perspective videos, missing out on the rich visual context of panoramic videos. With the increasing popularity of 360° cameras and advancements in virtual reality technology, generating matched spatial audio from panoramic videos has become an urgent issue to address.
To tackle these challenges, Qwen Lab proposed the 360V2SA (360-degree Video to Spatial Audio) task. FOA is a standard 3D spatial audio format represented by four channels (W, X, Y, Z), capable of capturing sound directionality and achieving realistic 3D audio reproduction, while maintaining accurate sound localization during head rotations.

Data is the cornerstone of machine learning models, but paired datasets of 360° videos and spatial audio are scarce. To address this, the research team carefully constructed the Sphere360 dataset, containing over 103,000 real-world video clips, covering 288 types of audio events, with a total duration of 288 hours. It includes both 360° visual content and supports FOA audio. During construction, the team adopted rigorous screening and cleaning standards, using various algorithms to ensure high-quality alignment.
The training method for OmniAudio is divided into two stages. In the first stage, self-supervised coarse-to-fine flow matching pretraining is used. The team fully utilized large-scale non-spatial audio resources, converting stereo audio into "pseudo-FOA" format before sending it into a four-channel VAE encoder to obtain latent representations. Random time-window masking was applied with a certain probability, treating the masked potential sequence and the complete sequence as conditional inputs to the flow-matching model, enabling self-supervised learning of audio timing and structure. This allowed the model to master general audio features and macro temporal rules. In the second stage, supervised fine-tuning based on dual-branch video representation was conducted. The team only used real FOA audio data, continuing to use the masked flow-matching training framework to strengthen the model's ability to represent sound source directions and improve the reconstruction of high-fidelity spatial audio details. After completing the self-supervised pretraining, the team combined the model with the dual-branch video encoder for supervised fine-tuning, precisely "carving" out FOA latent trajectories that match visual cues from noise, outputting four-channel spatial audio that is highly aligned with 360° videos and has precise directional sense.
In the experimental setup, the research team performed supervised fine-tuning and evaluation on the Sphere360-Bench and YT360-Test test sets, using objective and subjective metrics to measure the quality of the generated audio. The results showed that OmniAudio significantly outperformed all baselines on both test sets. On the YT360-Test set, OmniAudio greatly reduced values in FD, KL, and ΔAngular indicators; it also achieved excellent performance on the Sphere360-Bench. In human subjective assessments, OmniAudio scored much higher than the optimal baseline in terms of spatial audio quality and visio-audio alignment, demonstrating its superiority in clarity, spatial sense, and synchronization with visuals. Additionally, ablation experiments verified the contributions of the pretraining strategy, dual-branch design, and model scale to performance improvement.
Project Homepage
https://omniaudio-360v2sa.github.io/
Code and Data Open Source Repository
https://github.com/liuhuadai/OmniAudio
Paper Link
https://arxiv.org/abs/2504.14906