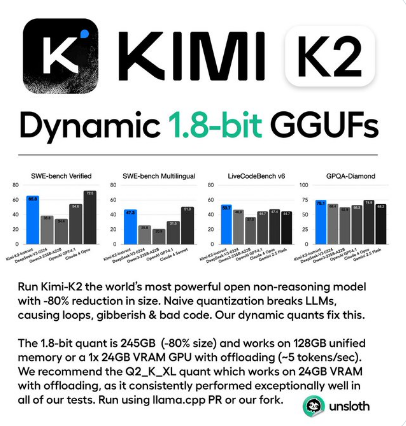
「深呼吸」让大模型表现更佳!谷歌DeepMind利用大语言模型生成Prompt,还是AI更懂AI
新智元
58
谷歌DeepMind提出了OPRO框架,使用大语言模型(LLM)进行优化,利用自然语言描述解决方案。其中「深呼吸」成为最佳Prompt提示词,提高模型性能。OPRO还在数学问题中表现出潜力,验证了提示优化在不同任务上的有效性,具有广泛应用前景。这项研究开拓了使用大语言模型进行优化任务的新方向,具有重要意义。
本文来自AIbase日报
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
—— 由AIbase 日报组创作
© 版权所有 AIbase基地 2024, 点击查看来源出处 -