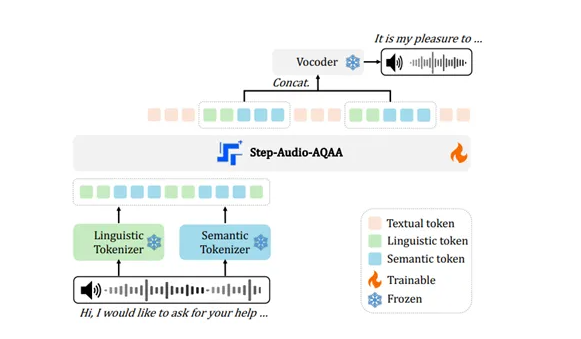
O Step-Audio2mini, o modelo de linguagem de áudio de código aberto mais forte da StepZen, foi oficialmente lançado em 1º de setembro. O modelo obteve resultados SOTA (State-of-the-Art) em vários conjuntos de benchmark internacionais, unificando a modelagem de compreensão de voz, raciocínio e geração de áudio. Ele se destaca nas tarefas de compreensão de áudio, reconhecimento de voz, tradução entre idiomas, análise de emoções e linguagem paralinguística, bem como diálogo de voz, e é o primeiro a oferecer capacidade nativa de chamada de ferramentas por voz, permitindo operações como pesquisa na internet. O Step-Audio2mini é descrito como "ouvir claramente, entender perfeitamente e falar naturalmente". O modelo já está disponível nos plataformas GitHub e Hugging Face, para download, teste e feedback pelos usuários.
O Step-Audio2mini obteve resultados SOTA em vários benchmarks importantes, destacando-se nas áreas de compreensão de áudio, reconhecimento de voz, tradução e cenários de diálogo, com desempenho superior a todos os modelos de linguagem de áudio de código aberto, incluindo Qwen-Omni e Kimi-Audio, e superando o GPT-4o Audio em maioria das tarefas. No conjunto de testes multimodal geral MMAU, o Step-Audio2mini obteve uma pontuação de 73,2, liderando os modelos de linguagem de áudio de código aberto; no URO Bench, que mede a capacidade de diálogo oral, o Step-Audio2mini obteve as maiores pontuações entre os modelos de linguagem de áudio de código aberto, tanto na categoria básica quanto na avançada; na tarefa de tradução entre chinês e inglês, o Step-Audio2mini obteve pontuações de 39,3 e 29,1 nos conjuntos de avaliação CoVoST2 e CVSS, superando significativamente o GPT-4o Audio e outros modelos de áudio de código aberto; no reconhecimento de voz, o Step-Audio2mini obteve os melhores resultados em múltiplos idiomas e dialetos, com uma taxa média de erro de palavra (WER) de 3,50 no conjunto de teste de inglês de código aberto e uma taxa média de erro de caractere (CER) de 3,19 no conjunto de teste de chinês de código aberto, superando outros modelos de código aberto em mais de 15%.

O Step-Audio2mini resolve efetivamente os problemas dos modelos anteriores por meio de um design inovador de arquitetura, sendo capaz de "pensar com a mente e sentir com o coração". Ele utiliza uma arquitetura multimodal verdadeiramente de ponta a ponta, superando a estrutura tradicional de ASR + LLM + TTS em três etapas, permitindo a conversão direta de entrada de áudio original para saída de resposta de voz, com uma arquitetura mais simples e menor latência, além de ser capaz de compreender efetivamente informações paralinguísticas e sinais não humanos. Além disso, o Step-Audio2mini introduz pela primeira vez na arquitetura de modelos de linguagem de áudio de ponta a ponta a combinação de raciocínio em cadeia (CoT) e otimização por reforço, permitindo compreensão, raciocínio e respostas naturais sobre linguagem paralinguística e sinais não de voz, como emoções, tom de voz e música. O modelo também suporta ferramentas externas, como busca na web, ajudando a resolver problemas de alucinação e proporcionando ao modelo capacidade de expansão em diversos cenários.
A capacidade do Step-Audio2mini é demonstrada de forma vívida em casos práticos. Ele pode identificar com precisão sons da natureza e dublagem excepcional, bem como pesquisar em tempo real informações atualizadas da indústria. Além disso, o Step-Audio2mini pode controlar a velocidade de fala, atendendo facilmente às necessidades de diálogo em diferentes cenários. Quando perguntado sobre dilemas filosóficos, o Step-Audio2mini consegue transformar questões abstratas em métodos simplificados, demonstrando uma forte capacidade de raciocínio lógico.
GitHub: https://github.com/stepfun-ai/Step-Audio2
Hugging Face: https://huggingface.co/stepfun-ai/Step-Audio-2-mini
ModelScope: https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini