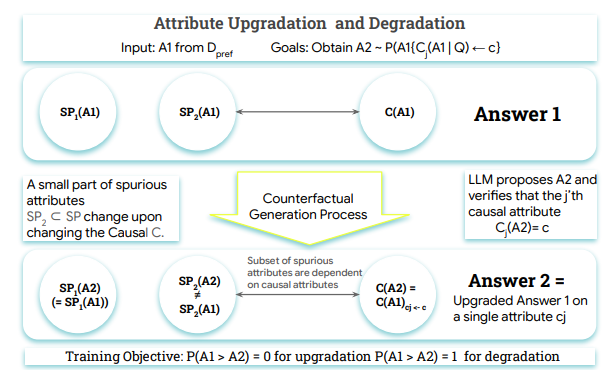
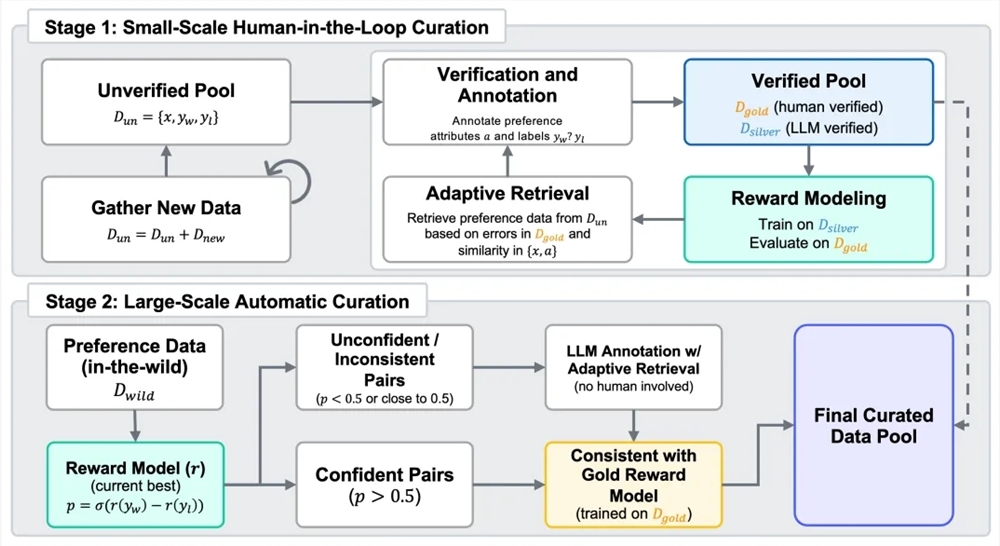
गूगल टीम के नवीनतम शोध ने यह प्रस्तावित किया है कि बड़े मॉडल का उपयोग मानवों के स्थान पर प्राथमिकता लेबलिंग के लिए किया जा सकता है, और इससे RLHF के समान परिणाम प्राप्त किए जा सकते हैं। शोधकर्ताओं ने RLAIF और RLHF की जीत की दर की तुलना करके पाया कि उनकी लोकप्रियता समान है, दोनों 50% है। यह शोध प्रमाणित करता है कि RLAIF मानव लेबलर्स पर निर्भर किए बिना RLHF के समान सुधार प्रभाव उत्पन्न कर सकता है।
RLHF अब मानवों की जरूरत नहीं! गूगल टीम का शोध प्रमाणित करता है कि AI लेबलिंग मानव स्तर तक पहुँच चुका है
新智元
73
यह लेख AIbase दैनिक से है
【AI दैनिक】 कॉलम में आपका स्वागत है! यहाँ आर्टिफ़िशियल इंटेलिजेंस की दुनिया का पता लगाने के लिए आपकी दैनिक मार्गदर्शिका है। हर दिन हम आपके लिए AI क्षेत्र की हॉट कंटेंट पेश करते हैं, डेवलपर्स पर ध्यान केंद्रित करते हैं, तकनीकी रुझानों को समझने में आपकी मदद करते हैं और अभिनव AI उत्पाद अनुप्रयोगों को समझते हैं।
—— AIbase दैनिक समूह द्वारा बनाया गया
© सर्वाधिकार सुरक्षित AIbase बेस 2024, स्रोत देखने के लिए क्लिक करें -