最近、趣丸科技はMaskGCTという新しい音声合成(TTS)モデルを発表しました。このモデルは、音声品質、類似度、制御可能性において顕著な進歩を遂げ、従来の音声合成(TTS)のやり方を根本的に変え、AIが人工的な注釈に頼ることなく、真の意味で「独学」を実現しました。

従来のTTSシステムは、まるで甘やかされて育った子供のように、一つ一つの言葉を人間が丁寧に教える必要がありました。テキストと音声の対応付けを行い、各音節の長さを予測し、やっとのことで音声合成が行われていました。この方法は、効率が悪いだけでなく、生成される音声にも自然で滑らかなリズムが欠けていました。
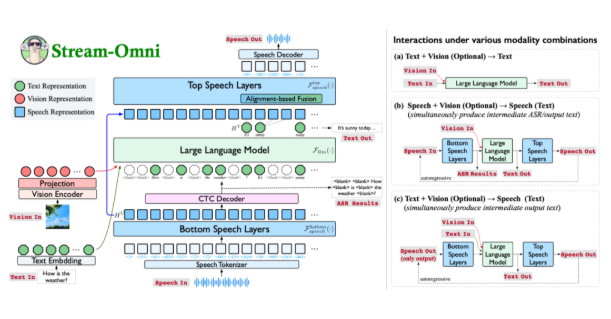
しかし、趣丸科技が今回発表したMaskGCTは、この古い方法を完全に捨てています。マスク付き生成型エンコーダデコーダTransformerアーキテクチャを採用しており、簡単に言うと、BERTのようなモデルを使用して、まず音声を意味特徴に変換し、これらの意味特徴に基づいて別のモデルで音響特徴を予測し、最終的に音声を合成します。
この方法の最大のポイントは、人工的な注釈が全く必要ないことです。10万時間もの注釈のない音声データを使用してトレーニングを行い、モデル自身が大量のデータからテキストと音声の対応関係を学習します。
まるで、子供を言語環境の中に放り込み、自分で試行錯誤しながら学習させ、自然に言語を習得させるようなものです。
MaskGCTのもう一つの優れた点は、人間のように音声の長さを柔軟に制御できることです。速くしたいなら速く、遅くしたいなら遅くできます。吹き替えや音声編集が必要な場面では、まさに朗報と言えるでしょう。
実験結果もMaskGCTの実力を証明しています。音声品質、類似度、リズム、明瞭さにおいて、既存の様々なTTSシステムを凌駕し、人間の声と遜色ないレベルに達しています。
さらに驚くべきことに、MaskGCTは高品質の音声を生成できるだけでなく、異なる話者のスタイルを模倣したり、言語を跨いでの音声翻訳も可能です。まさに万能選手と言えるでしょう。
もちろん、MaskGCTにはまだいくつかの限界があります。例えば、大幅な顔の姿勢の変化を伴う音声合成では、多少の欠陥が生じる可能性があります。しかし、欠点よりも長所がはるかに大きく、MaskGCTの登場は、TTS分野に新たな地平を開き、未来の人間と機械のインタラクション体験に無限の可能性をもたらしました。
オンライン体験:https://huggingface.co/spaces/amphion/maskgct
プロジェクトアドレス:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
公式サイトアドレス:https://voice.funnycp.com/