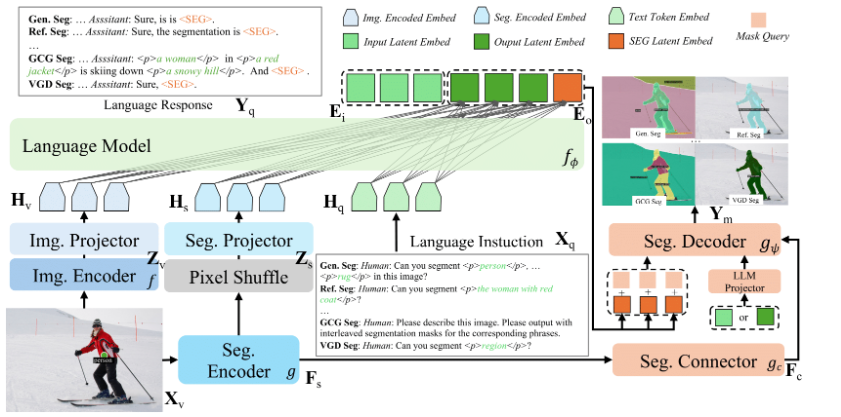
El Laboratorio de Inteligencia Artificial de Shanghai (Shanghai AI Lab) anunció el 31 de agosto la liberación de código abierto del modelo de gran escala multimodal Shueng·Wanxiang InternVL3.5. Este modelo logró una mejora integral en capacidad de razonamiento, eficiencia de implementación y capacidad general mediante un aprendizaje por refuerzo en cascada (Cascade RL), una ruta de resolución visual dinámica y un marco de despliegue desacoplado. InternVL3.5 puso a disposición versiones completas de todos los tamaños de parámetros, desde 1B hasta 241B, rompiendo así el estándar de rendimiento de modelos de código abierto y alcanzando niveles líderes en diversas tareas.
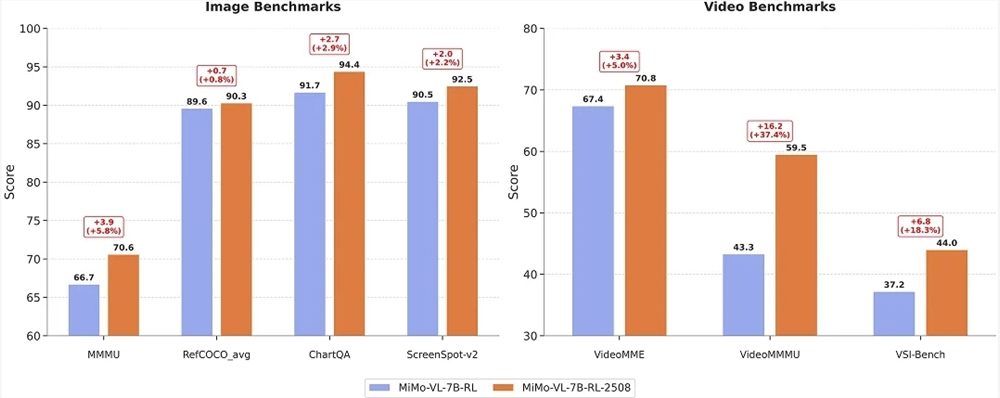
El modelo principal de InternVL3.5, InternVL3.5-241B-A28B, obtuvo la puntuación más alta entre los modelos de código abierto en el conjunto de pruebas MMMU de razonamiento interdisciplinario con 77,7 puntos. En los benchmarks de percepción multimodal MMStar y OCRBench, alcanzó respectivamente 77,9 y 90,7 puntos, superando a GPT-5 (75,7/80,7). En los benchmarks de razonamiento textual AIME25 y MMLU-Pro, alcanzó 75,6 y 81,3 puntos, superando ampliamente a los modelos multimodales de código abierto existentes. Gracias al marco de aprendizaje por refuerzo en cascada, el rendimiento de razonamiento de toda la serie de modelos mejoró en promedio 16,0 puntos en comparación con la generación anterior. Entre ellos, el InternVL3.5-241B-A28B alcanzó un rendimiento de razonamiento integral de 66,9 puntos, superando al modelo anterior de 54,6 puntos y al Claude-3.7-Sonnet de 53,9 puntos, destacando especialmente en tareas complejas como el razonamiento matemático y lógico.

Gracias a la innovadora ruta de resolución visual (ViR) y al marco de despliegue desacoplado (DvD), la velocidad de respuesta del modelo de 38B aumentó significativamente en resolución de 896, reduciendo el retraso de una sola inferencia de 369 ms a 91 ms (un aumento de aproximadamente 4 veces). Al mismo tiempo, el InternVL3.5-Flash, que es ligero, mantuvo casi el 100% del nivel de rendimiento mientras reducía a la mitad la longitud de la secuencia visual.
InternVL3.5 también fortaleció las capacidades clave de agentes inteligentes, como agentes de interfaz gráfica de usuario (GUI), agentes corporales, comprensión y generación de SVG. En tareas como la localización de GUI ScreenSpot (92,9 puntos), razonamiento espacial de VSI-Bench (69,5 puntos) y comprensión de gráficos vectoriales de SGP-Bench (70,6 puntos), superó a los modelos de código abierto principales.
InternVL3.5 ofrece nueve tamaños de modelos con parámetros de 1.000 millones a 241.000 millones, cubriendo diferentes escenarios de necesidad de recursos, incluyendo modelos densos y modelos de mezcla de expertos (MoE). Es el primer modelo multimodal de código abierto que admite la base del modelo de lenguaje GPT-OSS. La versión oficial proporciona ejemplos de código para ejecutar InternVL3.5-8B con `transformers`. El modelo puede implementarse en una sola tarjeta gráfica A100, mientras que el modelo de 38B requiere dos tarjetas A100 y el modelo de 235B requiere ocho tarjetas A100.
ms-swift ya admite el entrenamiento de la serie de modelos InternVL3.5. ms-swift es un marco de entrenamiento y despliegue de modelos grandes y modelos multimodales proporcionado oficialmente por la comunidad Moba. Los usuarios pueden preparar sus datos en un formato específico para realizar ajuste fino con conjuntos de datos personalizados. Después del entrenamiento, pueden usar comandos correspondientes para realizar inferencias y enviar el modelo a ModelScope.
La lanzamiento de InternVL3.5 marca otro avance importante en la tecnología de modelos grandes multimodales, brindando a investigadores y desarrolladores herramientas poderosas y impulsando el desarrollo de la inteligencia artificial multimodal.
Método de uso del código abierto/modelo:
https://github.com/OpenGVLab/InternVL
Conjunto de modelos:
https://www.modelscope.cn/collections/InternVL35-Full-3871e58bf21349
Experiencia en línea:
https://chat.intern-ai.org.cn/