High-Resolution AI Model Griffon v2: Flexible Text and Visual Referencing
站长之家
158
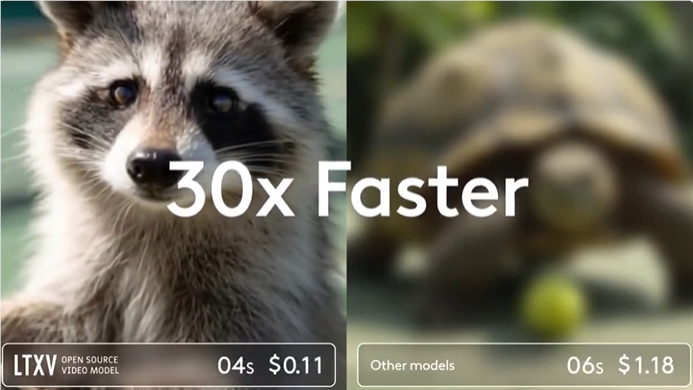
The latest high-resolution AI model, Griffon v2, integrates text and visual cues to provide flexible object references. The team has enhanced multimodal perception capabilities by using a downsampling projector. This model excels in tasks such as reference expression generation, phrase localization, and reference expression understanding, outperforming expert models. It features a visual-language coreference structure, demonstrating superior performance in object detection and object counting.
This article is from AIbase Daily
Welcome to the [AI Daily] column! This is your daily guide to exploring the world of artificial intelligence. Every day, we present you with hot topics in the AI field, focusing on developers, helping you understand technical trends, and learning about innovative AI product applications.
—— Created by the AIbase Daily Team
© Copyright AIbase Base 2024, Click to View Source -