最近、アリババのQwenチームの研究者らは、言語モデルの数学的推論における過程の誤りを識別する能力を測定することを目的とした、"PROCESSBENCH"という新しいベンチマークを発表しました。複雑な推論タスクにおいて言語モデルが著しい進歩を遂げる中、研究者らは、モデルは優れた性能を示すものの、一部の難しい問題を処理する際には依然として課題に直面していることを発見しました。そのため、効果的な監督方法の開発が非常に重要になります。

現在、言語モデルの評価ベンチマークにはいくつかの欠点があります。一つは、いくつかの問題集が高度なモデルにとっては簡単すぎることです。もう一つは、既存の評価方法は、二元的な正誤判定しか提供せず、詳細な誤りの注釈が不足していることです。この現象は、複雑な言語モデルの推論メカニズムをより深く考察するための、より包括的な評価フレームワークが緊急に必要であることを浮き彫りにしています。
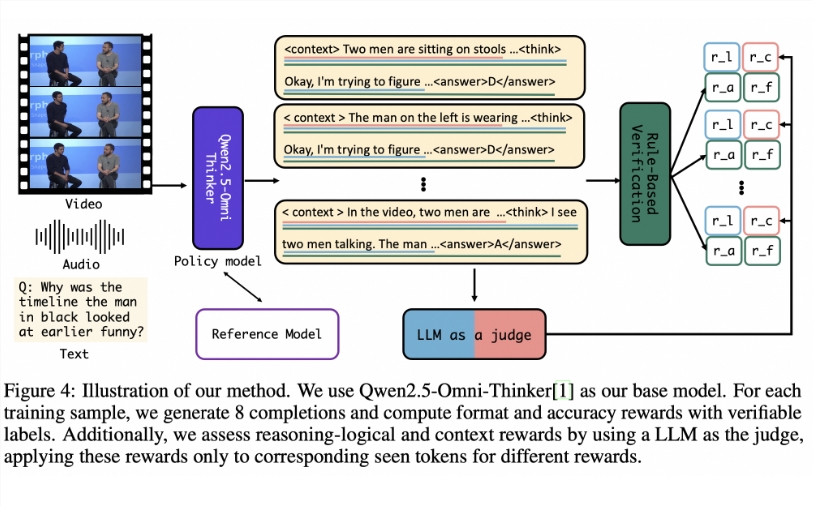
このギャップを埋めるために、研究者らは"PROCESSBENCH"を設計しました。このベンチマークは、数学的推論における誤ったステップの識別に焦点を当てています。その設計原則には、問題の難易度、解法の多様性、包括的な評価が含まれます。このベンチマークは、競技会やオリンピックレベルの数学の問題を対象とし、複数のオープンソース言語モデルを使用して、異なる解法を示す解答を生成します。PROCESSBENCHは、複数の専門家によって注意深く注釈が付けられた3400個のテストケースを含み、データの質と評価の信頼性を確保しています。

開発過程において、研究チームは4つの有名なデータセット(GSM8K、MATH、OlympiadBench、Omni-MATH)から数学の問題を集め、小学校レベルから競技会レベルまでの幅広い難易度を網羅しています。彼らはオープンソースモデルを使用して最大12種類の異なる解法を生成し、解法の多様性を高めました。さらに、解法手順のフォーマットを統一するために、研究チームは再フォーマット化の方法を採用し、論理的に完全な段階的な推論を確保しました。
研究結果によると、既存のプロセス報酬モデルは、特に簡単な問題集では、高度な問題に対処する際に性能が劣り、プロンプト駆動型の評価モデルの方が優れた性能を示しました。この研究は、既存のモデルが数学的推論を評価する際の限界、特にモデルが誤った中間ステップを経て正しい答えに到達した場合に正確に判断することが難しいことを明らかにしています。
PROCESSBENCHは、言語モデルの数学的推論における誤りを識別する能力を評価するための先駆的なベンチマークとして、将来の研究のための重要なフレームワークを提供し、推論過程におけるAIの理解と改善を促進します。
論文へのリンク:https://github.com/QwenLM/ProcessBench?tab=readme-ov-file
コード:https://github.com/QwenLM/ProcessBench?tab=readme-ov-file
要点:
🌟 研究チームが発表した新しいベンチマーク"PROCESSBENCH"は、言語モデルが数学的推論における誤りを識別する能力を評価することを目的としています。
📊 PROCESSBENCHは、様々な難易度の数学の問題を含み、専門家によって注意深く注釈が付けられた3400個のテストケースで構成されています。
🔍 研究では、既存のプロセス報酬モデルは高度な問題において性能が劣ることが明らかになり、誤り識別戦略の改善が求められています。