威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员开源了多模态大模型LLaVA-1.5,该模型在11项基准测试中表现出卓越性能,包括视觉问答和图像caption任务。LLaVA-1.5仅需8个A100 GPU,在1天内完成训练,性能显著。研究人员提出了在微调过程中添加输出格式提示的方法,使模型能够更好地适应不同任务。LLaVA-1.5的强大多模态理解能力挑战了GPT-4V的地位。
相关AI新闻推荐

脑虎科技创始人彭雷预测脑机接口未来五年五大颠覆性趋势
在2025亚布力中国企业家论坛第十一届创新年会上,脑虎科技创始人兼董事长彭雷深入探讨了脑机接口(BCI)技术的未来发展,并提出了未来五年该领域的五大新趋势,这些趋势有望彻底改变人类的生活方式和科技格局。1. 脑机与脊髓结合:瘫痪患者的希望彭雷指出,脑机接口与脊髓的结合将是未来一大趋势。由于大脑和脊髓紧密相连,高位截瘫患者的脊髓损伤阻碍了神经信号的传导。未来,通过在头部植入脑机接口并在背部植入髓机接口,有望使瘫痪患者重新站立,恢复行动能力。2. 视觉
2025年7月4号 11:44
230

揭开大模型的秘密!那些 “思考词” 背后藏着惊人的信息量
近日,来自中国人民大学、上海人工智能实验室、伦敦大学学院和大连理工大学的研究团队揭示了大模型推理过程中的一个重要发现:当模型在思考时,所使用的 “思考词” 实际上反映了其内部信息量的显著提升。这一研究成果通过信息论的方法,为我们更好地理解人工智能的推理机制提供了新的视角。你或许见过大模型在解答问题时,会输出一些看似人类化的语言,比如 “嗯……”、“让我想想……” 或 “因此……”。这些 “思考词” 是简单的表面装饰,还是代表着模型真正的思考
2025年7月4号 11:22
400
DeepMind 推出 Crome:提升大型语言模型对人类反馈的对齐能力
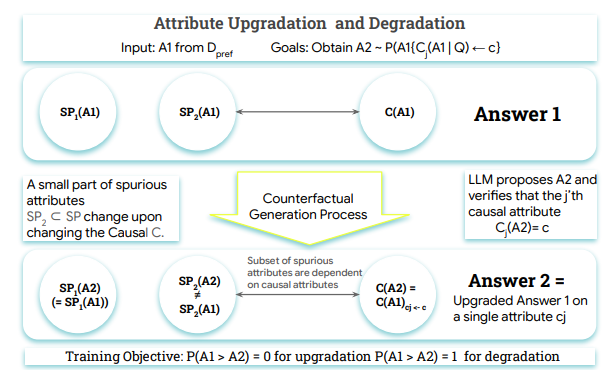
在人工智能领域,奖励模型是对齐大型语言模型(LLMs)与人类反馈的关键组成部分,但现有模型面临着 “奖励黑客” 问题。这些模型往往关注表面的特征,例如回复的长度或格式,而不是识别真正的质量指标,如事实准确性和相关性。问题的根源在于,标准训练目标无法区分训练数据中存在的虚假关联和真实的因果驱动因素。这种失败导致了脆弱的奖励模型(RMs),从而生成不对齐的策略。为了解决这一问题,需要一种利用因果理解来训练 RMs 的新方法,以便对因果质量属性敏感,并对
2025年7月4号 11:09
220

MiniMax 发布全球首个开源大规模 AI 模型,技术突破引发行业关注
近日,上海的 AI 独角兽公司 MiniMax 正式推出了全球首个开源大规模混合架构推理模型 ——MiniMax-M1。该模型一经推出,便迅速跻身权威评测榜单,成为全球开源模型的第二名,仅次于近期发布的 DeepSeek-R1-0528。这一里程碑式的成就让 MiniMax 创始人兼 CEO 闫俊杰在社交媒体上感慨:“第一次感觉到大山不是不能翻越。”MiniMax-M1的亮相不仅令人瞩目,其在技术细节上的表现更是出色。该模型在长文本处理和工具调用等方面显示出强大的优势,支持高达100万 token 的上下文输入能力,足以一次性处理
2025年7月4号 10:21
1.3k
昆仑万维再次开源奖励模型Skywork-Reward-V2
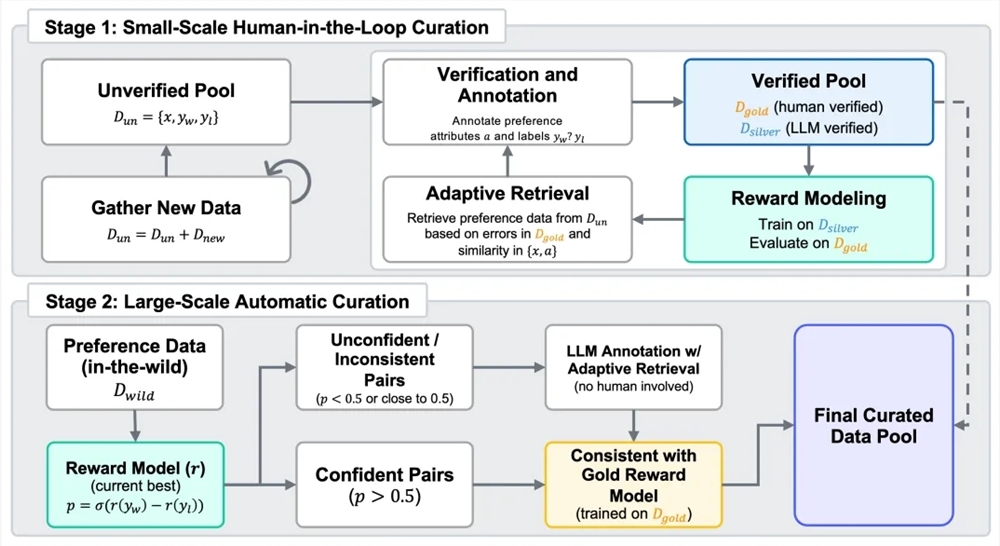
2025年7月4日,昆仑万维乘势而上,继续开源第二代奖励模型Skywork-Reward-V2系列。此系列共包含8个基于不同基座模型、参数规模从6亿到80亿不等的奖励模型,一经推出便在七大主流奖励模型评测榜单中全面夺魁,成为开源奖励模型领域的焦点。 奖励模型在从人类反馈中强化学习(RLHF)过程中起着关键作用。为打造新一代奖励模型,昆仑万维构建了包含4000万对偏好对比的混合数据集Skywork-SynPref-40M。在数据处理上,团队采用人机协同的两阶段流程,将人工标注的高质量与模型的规模化处理能力相结合。第一阶段,先构建未经验证的初始偏好池,借助
2025年7月4号 10:02
690

谷歌Veo 3视频生成模型向 Pro / Ultra 会员开放,将新增“照片生成视频”功能
谷歌在全球范围内宣布其最新一代AI文生视频模型 Veo3 正式向 Google AI Pro 和 Ultra 会员开放。这款由 Google DeepMind 研发的视频生成模型,以其卓越的高清画质、音画同步能力以及多模态创作功能,迅速成为AI视频生成领域的焦点。Veo3:重新定义AI视频生成在2025年 Google I/O 开发者大会上首次亮相的 Veo3,被誉为谷歌在AI视频生成领域的里程碑式产品。相比前代模型,Veo3在以下方面实现了显著突破:高清画质与物理真实感:Veo3支持生成 1080p 高清视频,内部测试甚至可达 4K 分辨率。其视频画面不仅细节
2025年7月4号 9:53
820

中国医疗大模型发布量占全球70%!毕马威揭示未来市场潜力
根据毕马威中国最近发布的《首届健康科技50》报告,中国在全球医疗大模型的发布数量上占据了令人瞩目的70% 以上。这一数据不仅展现了中国在智能医疗领域的快速发展,也反映了大语言模型在医疗行业的广泛应用。报告指出,目前已经发布的医疗大模型中,大语言模型的数量占据了约65%。这类模型能够处理和生成自然语言,对于医疗数据的分析、患者交流及科研都有着重要的支持作用。而中国的表现尤为突出,其发布的医疗大模型数量不仅领先于其他国家,更是在全球市场中扮演着关
2025年7月4号 9:41
490

OpenAI 版权诉讼新进展:《纽约时报》将可访问已删除的用户数据
在《纽约时报》起诉 OpenAI 的长期版权侵权诉讼中,案件取得了重大进展。据 Ars Technica 报道,审理此案的联邦法官已授权《纽约时报》及其共同原告《纽约每日新闻》和调查报道中心,访问 OpenAI 的用户日志,包括已删除的内容,以精确查明侵权范围。《纽约时报》认为,ChatGPT 用户可能会在绕过付费墙后删除历史记录,因此有必要进行大规模的数据覆盖。该报进一步声称,这些日志的搜索结果可能成为整个诉讼的关键证据:OpenAI 的大型语言模型(LLM)不仅使用了其受版权保护的材料进行训
2025年7月4号 9:21
510

小鹏 G7 Ultra 重磅登场!全新智能驾驶大模型震撼发布
在新能源汽车市场上,小鹏汽车再度引发关注。7月3日,小鹏 G7Ultra 正式上市,成为首款搭载本地端 “VLA+VLM” 大模型的智能汽车。这一创新技术的推出,标志着小鹏在智能驾驶领域迈出了重要一步。小鹏 G7Ultra 配备了 VLA(主动思考与迅速决策能力)大模型,让驾驶体验更为智能化。在日常驾驶中,G7Ultra 能够灵活应对各种复杂行驶场景,比如在拥堵的路段主动选择最佳绕行路线,或在遇到积水路面时自动减速,以确保行车安全。这些智能化功能让 G7Ultra 不仅是一个代步工具,更是一个能
2025年7月4号 8:52
1.2k

A日报:B站升级动漫视频生成模型AniSora V3;字节开源4D视频生成框架EX-4D;DeepSWE开源AI Agent系统强势登顶
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、字节跳动EX-4D震撼开源:单目视频秒变自由视角4D大片EX-4D是字节跳动PICO-MR团队推出的4D视频生成框架,能够从单目视频生成高质量、多视角的4D视频序列。该技术通过深度密闭网格(DW-Mesh)和轻量级适配架构,解决了传统视频生成技术在多视角生成中的挑战,并在性能指标上全面领先。【AiBase
2025年7月3号 16:27
2.8k