文章深入研究大型语言模型的训练成本,包括硬件、模型架构、训练动态和优化方法等多个方面。OpenAI宣布构建一款模型的起始费用高达200-300万美元,引发业界讨论。文章深入研究硬件成本、模型结构和训练动态,强调优化这些方面是降低训练成本的关键。
相关AI新闻推荐

重大突破!研究团队揭示大语言模型内部潜藏的 “奖励机制”
近日,南京大学的周志华教授团队发布了一项重要研究,首次理论证明了在大语言模型中可以发现内源性奖励模型,并有效应用强化学习(RL)来提升模型表现。当前,许多对齐方法依赖于人类反馈强化学习(RLHF),这种方法需要大量高质量的人类偏好数据来训练奖励模型。然而,构建这样一个数据集不仅耗时费力,还面临成本高昂的挑战。因此,研究者们开始探索替代方案,其中基于 AI 反馈的强化学习(RLAIF)受到关注。这种方法利用强大的大语言模型自身生成奖励信号,以降低对人类标
2025年7月2号 17:50
860

百度发布全球首个中文音视频生成模型 MuseSteamer,颠覆创作方式
近日,百度商业研发团队于7月2日宣布推出一款革命性的视频生成模型 “MuseSteamer”,并同时发布了创作平台 “绘想”。这一创新的技术标志着全球首个实现中文音视频一体化生成的模型正式问世,必将为内容创作领域带来深远的影响。MuseSteamer 的最大亮点在于其卓越的协同创作能力,能够将画面、音效以及人声台词完美结合,生成高质量的视频内容。根据官方介绍,该模型在权威榜单 VBench I2V 中获得了89.38% 的总分,荣登全球第一。这一成绩不仅体现了其强大的技术实力,也为内容创作者
2025年7月2号 17:40
680

京东具身智能战略全面提速 JoyInside合作版图曝光
据网易科技报道,京东在具身智能领域的布局正在全面提速。京东旗下具身智能品牌JoyInside已与十余家头部机器人企业达成合作,成为京东抢占智能机器人市场的核心引擎。据知情人士透露,JoyInside由京东大模型技术支持,专注于提供机器人与消费者的智能互动能力,其产品策略聚焦于"一人一狗一玩具"的场景化应用。该品牌自推出以来,已成功吸引了多个细分领域的头部企业加入合作阵营。在家庭陪伴场景中,魔法原子MagicDog Pro四足机器狗、念NIA-F01人形机器人、"璇玑"蛋形机器人等产品
2025年7月2号 17:12
850

富士康推出首款AI推理大模型 “FoxBrain”,商标申请已提交
近日,鸿海精密工业股份有限公司(也就是大家熟悉的富士康)在国家知识产权局商标局提交了 “FoxBrain” 商标注册申请。这款 AI 推理大模型不仅是富士康的首次尝试,更是台湾地区首个该类型的 AI 模型。根据公开资料显示,该商标的国际分类为科学仪器,目前正处于 “等待实质审查” 的状态。“FoxBrain” 是鸿海研究院重磅推出的 AI 推理大模型,涵盖数据分析、数学推理、代码生成等多个功能,功能丰富,极具潜力。富士康声称,FoxBrain 的初始版本基于 Meta 的 Llama3.1模型进行开发,使
2025年7月2号 17:09
690

智谱AI重磅开源GLM-4.1V-Thinking!多模态推理新王者,挑战全球顶尖模型
中国人工智能领域的领军企业智谱AI(Zhipu AI)再次掀起行业热潮。AIbase最新获悉,智谱AI于近日正式开源其新一代通用视觉模型GLM-4.1V-Thinking。这款9亿参数的多模态推理模型凭借卓越的性能和广泛的应用场景,不仅在多项权威评测中刷新纪录,还展现了比肩甚至超越72亿参数模型的强大实力。以下是AIbase整理的最新资讯,带您深入了解这一突破性技术。引入思维链推理,性能大幅提升GLM-4.1V-Thinking基于智谱AI此前的GLM-4V架构进行了深度优化,引入了创新的思维链推理机制(Chain-of-Thought Reason
2025年7月2号 16:54
880
智谱AI开源GLM-4.1V-Thinking:多模态推理模型再突破
智谱AI正式开源最新一代通用视觉模型GLM-4.1V-Thinking,基于GLM-4V架构,新增思维链推理机制,显著提升复杂认知任务能力。该模型支持图像、视频、文档等多模态输入,擅长长视频理解、图像问答、学科解题、文字识别、文档解读、Grounding、GUI Agent及代码生成等多样化场景,覆盖千行百业的应用需求。GLM-4.1V-9B-Thinking在28项权威评测中表现卓越,其中23项达成10B级模型最佳成绩,18项持平或超越72B参数的Qwen-2.5-VL,涵盖MMStar、MMMU-Pro、ChartQAPro、OSWorld等基准测试。其9亿参数规模结合高效推理能力
2025年7月2号 16:31
980
AI日报:百度发布“绘想”平台与MuseSteamer;阿里音频驱动全身数字人模型OmniAvatar
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、开源端到端语音大模型Step-Audio-AQAA:听懂音频直接生成自然语音Step-Audio-AQAA 是一个开源的端到端语音大模型,能够直接从原始音频输入生成自然流畅的语音输出,显著提升了人机交互的体验。该模型由双码本音频标记器、骨干 LLM 和神经声码器三部分组成,能够高效处理语音中的复杂信息,
2025年7月2号 16:24
850
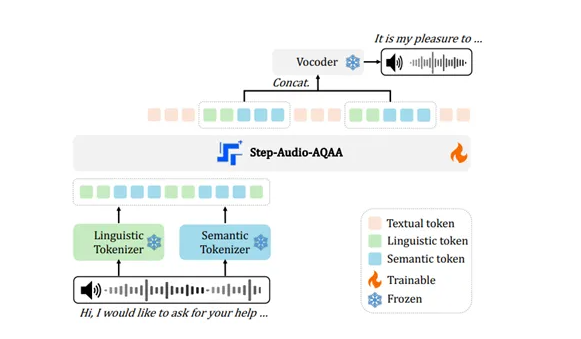
开源端到端语音大模型Step-Audio-AQAA:听懂音频直接生成自然语音
在人工智能领域,尤其是生成式对抗网络(AIGC)方面的不断进展,语音交互已成为一个重要的研究方向。传统的大语言模型(LLM)主要专注于文本处理,无法直接生成自然语音,这在一定程度上影响了人机音频交互的流畅性。为了突破这一局限,Step-Audio 团队开源了一款全新的端到端语音大模型 ——Step-Audio-AQAA。该模型能够直接从原始音频输入生成自然流畅的语音输出,使得人机交流更加自然。Step-Audio-AQAA 的架构由三个核心模块组成:双码本音频标记器、骨干 LLM 和神经声码器。其中,双码本
2025年7月2号 16:19
1.1k
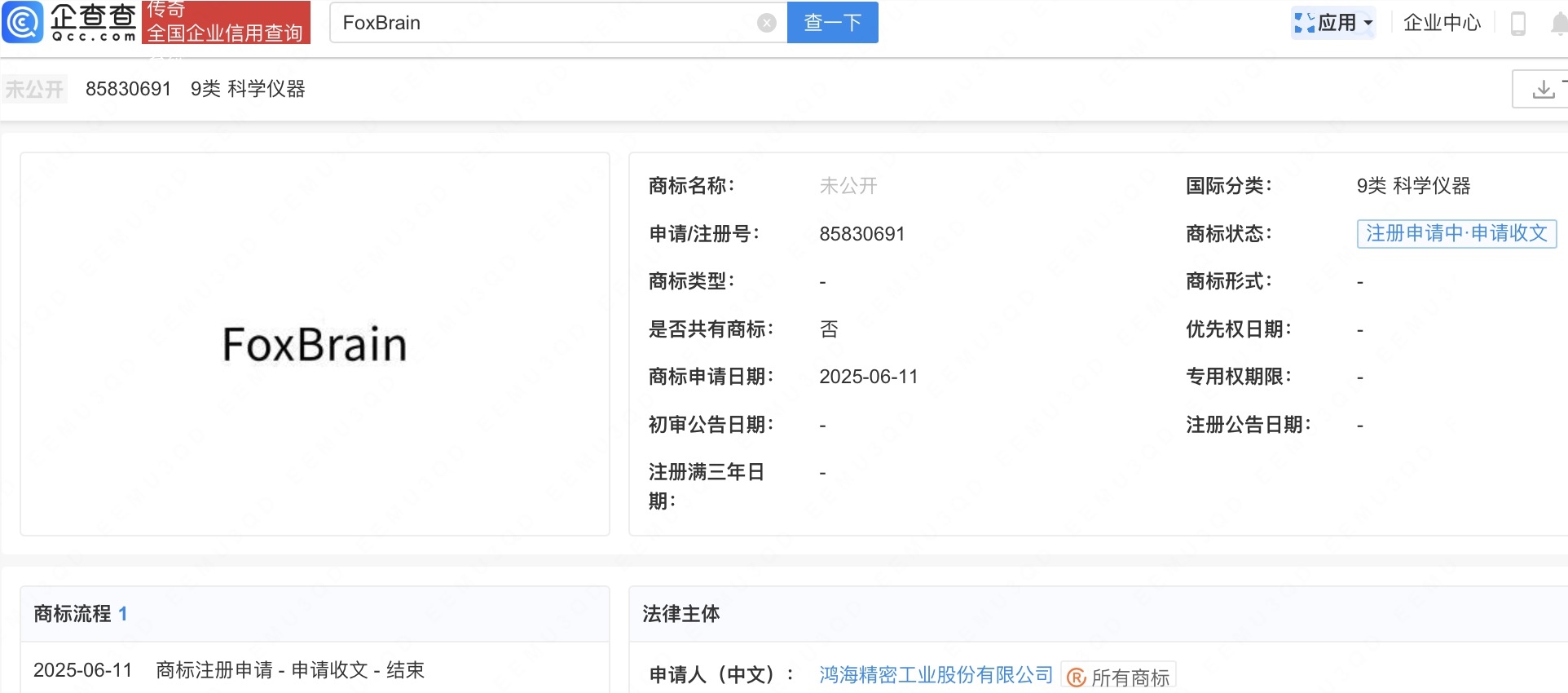
富士康母公司注册AI推理大模型商标
企查查APP显示,近日,鸿海精密工业股份有限公司申请注册“FoxBrain”商标,国际分类为科学仪器,当前商标状态为注册申请中。据媒体报道,FoxBrain是鸿海集团(富士康)旗下鸿海研究院自主研发的首款繁体中文AI推理大模型。该模型于今年3月正式发布,基于Meta Llama3.1架构开发优化,专注于数学推演、逻辑分析与代码生成领域。
2025年7月2号 15:46
370

浙大与阿里联合发布OmniAvatar:音频驱动全身数字人模型震撼登场
浙江大学与阿里巴巴联合推出全新音频驱动模型OmniAvatar,标志着数字人技术迈向新高度。该模型以音频为驱动,可生成自然流畅的全身数字人视频,尤其在歌唱场景下表现突出,口型与音频唇形同步精准,效果逼真。OmniAvatar支持通过文本提示精细控制生成细节,用户可自定义人物动作幅度、背景环境及情绪表达,展现出极高的灵活性。此外,该模型能够生成虚拟人物与物体互动的视频,为电商广告、营销广告等商业场景提供了广阔应用空间。例如,品牌可利用OmniAvatar制作动态广告,增强
2025年7月2号 15:33
560