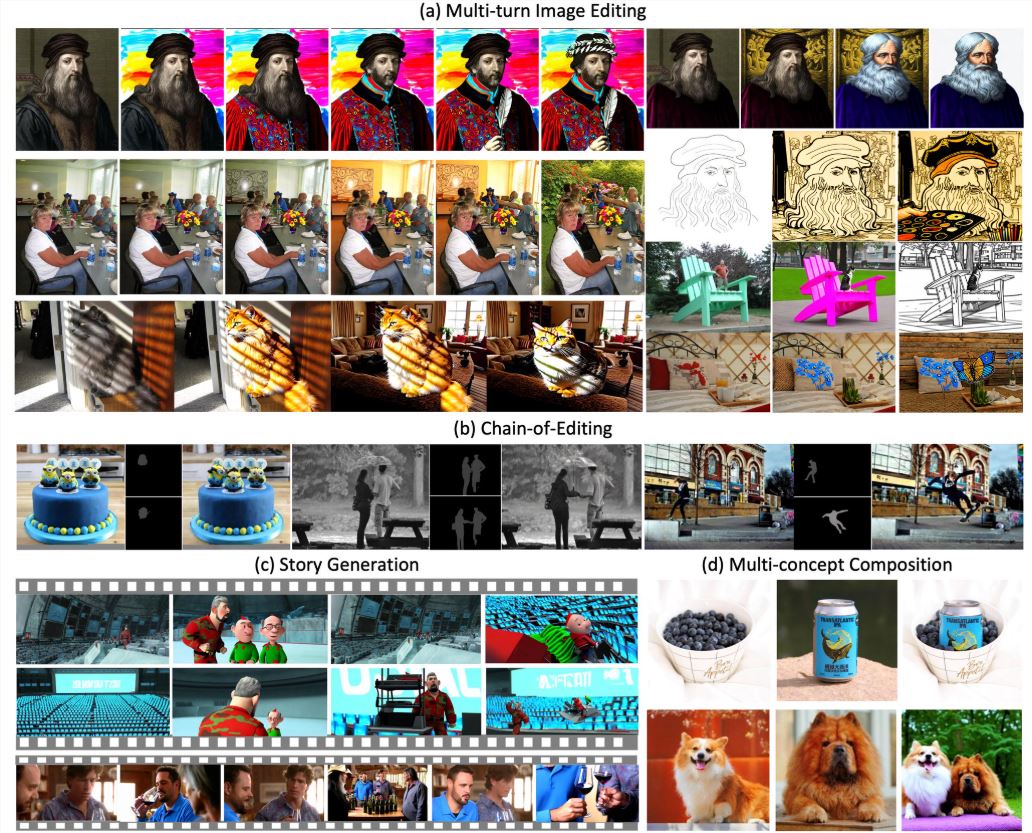
谷歌发布开源大模型 Gemme,转变开源策略
甲子光年
52
谷歌发布了开源大模型 Gemme,标志着转变了去年的闭源策略。Gemme 包括 Gemma 2B 和 Gemma 7B 两种规模的模型,支持预训练和微调。谷歌的开源举措与 Meta 和 Mistral 形成三巨头局面,构成大模型市场的打压链。专家认为,谷歌之所以转向开源,可能是被迫应对 OpenAI 等竞争对手的压力。
本文来自AIbase日报
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
—— 由AIbase 日报组创作
© 版权所有 AIbase基地 2024, 点击查看来源出处 -