MoMask: A Text-Driven 3D Human Motion Generation Model
站长之家
363
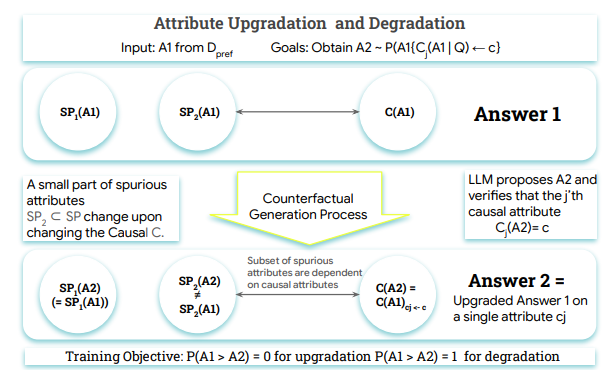
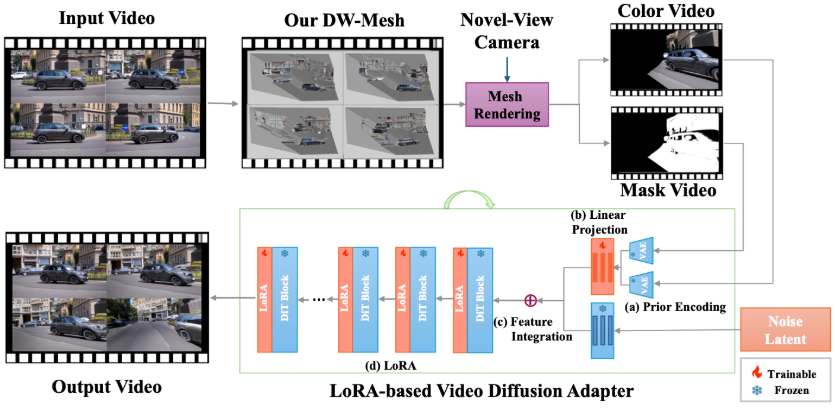
MoMask is an innovative 3D human motion generation model that utilizes a hierarchical quantization scheme to represent actions, consisting of a base layer and progressively added residual markers. The model architecture introduces Masked Transformer and Residual Transformer to predict the mask action markers for the base layer and gradually predict higher-level markers. In text-to-motion generation tasks, MoMask demonstrates exceptional performance, achieving an FID of 0.045 on the HumanML3D dataset, significantly surpassing other models.
This article is from AIbase Daily
Welcome to the [AI Daily] column! This is your daily guide to exploring the world of artificial intelligence. Every day, we present you with hot topics in the AI field, focusing on developers, helping you understand technical trends, and learning about innovative AI product applications.
—— Created by the AIbase Daily Team
© Copyright AIbase Base 2024, Click to View Source -