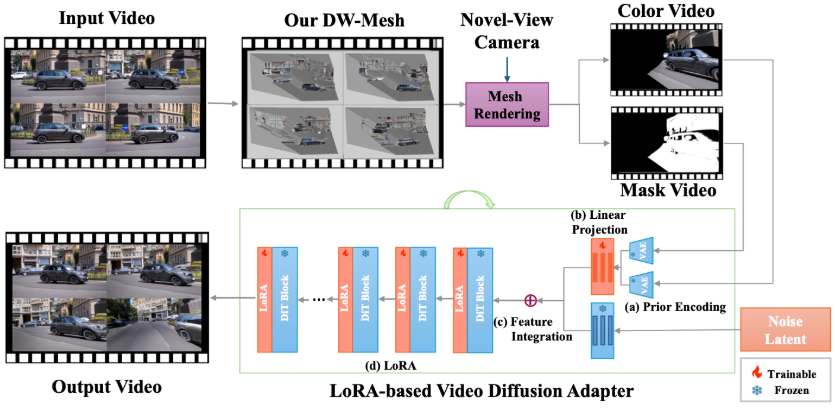
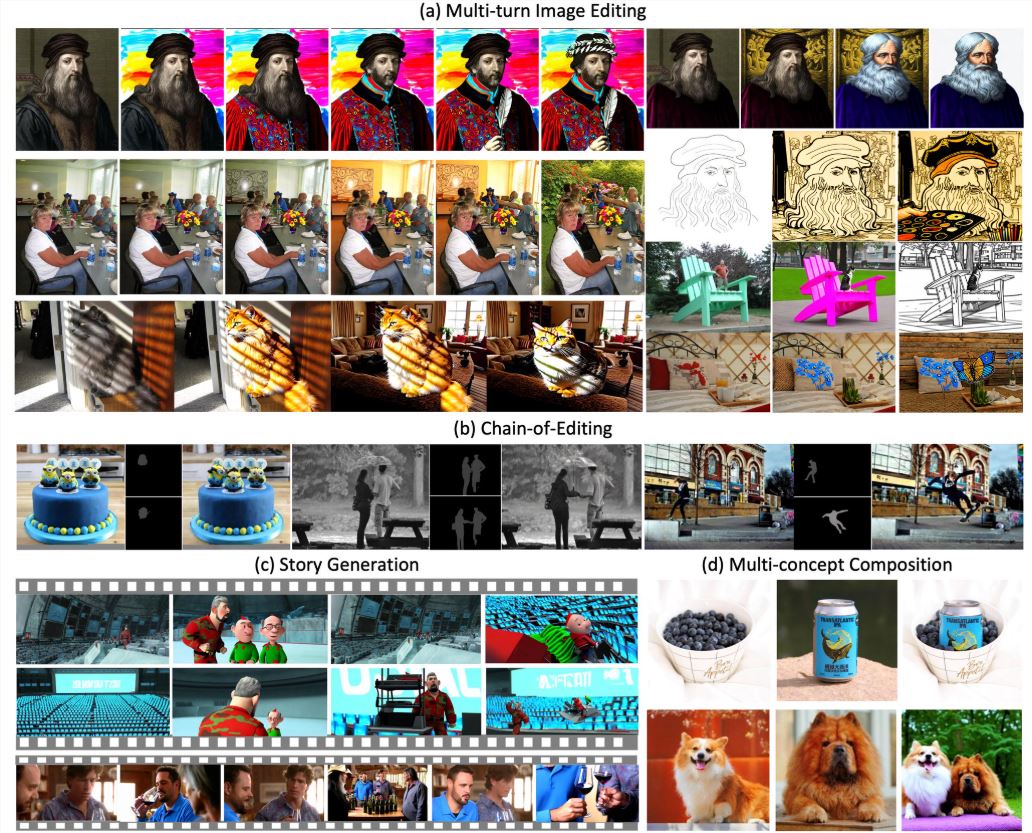
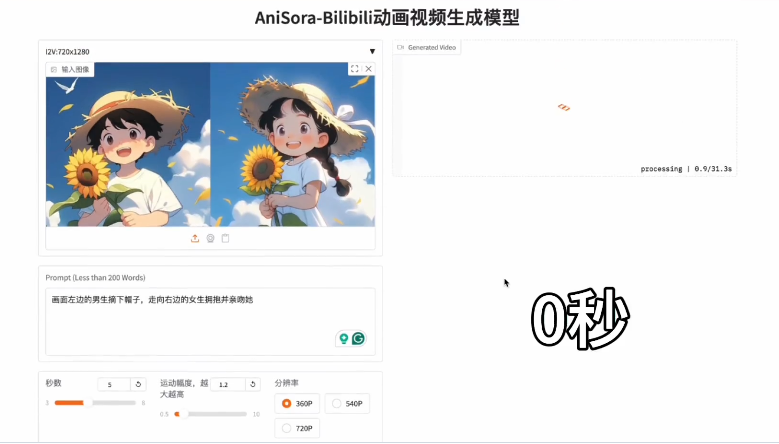
A Zhipu AI lançou oficialmente a nova geração do modelo de visão geral GLM-4.1V-Thinking, baseado na arquitetura GLM-4V, com a adição de um mecanismo de raciocínio em cadeia, que melhora significativamente a capacidade de tarefas cognitivas complexas. Este modelo suporta entradas multimodais como imagens, vídeos e documentos, sendo especializado em compreensão de vídeos longos, perguntas e respostas sobre imagens, resolução de problemas de disciplinas, reconhecimento de texto, interpretação de documentos, Grounding, GUI Agent e geração de código, atendendo às necessidades de aplicação de milhares de indústrias.
O GLM-4.1V-9B-Thinking obteve excelentes resultados em 28 avaliações autorizadas, alcançando o melhor desempenho de modelos com 10B parâmetros em 23 delas e igualando ou superando os modelos Qwen-2.5-VL com 72B parâmetros em 18 delas, incluindo benchmarks como MMStar, MMMU-Pro, ChartQAPro e OSWorld. Com 9 bilhões de parâmetros e uma eficiente capacidade de raciocínio, ele pode ser executado em uma única placa de vídeo 3090, além de oferecer uma licença gratuita para uso comercial, reduzindo significativamente a barreira para os desenvolvedores.
A Zhipu AI afirma que o GLM-4.1V-Thinking otimizou sua capacidade de raciocínio transversal por meio de técnicas de aprendizado reforçado e amostragem de currículo, demonstrando profundidade de pensamento e capacidade de resolução de problemas complexos. O modelo foi lançado no HuggingFace, permitindo que desenvolvedores de todo o mundo o experimentem gratuitamente. A indústria acredita que essa iniciativa impulsionará o uso amplo de IA multimodal nas áreas de educação, pesquisa e negócios, marcando mais um marco na jornada da Zhipu AI em direção à inteligência artificial geral.